Importmodul III: Datenverarbeitung |
Da jede Vorgabe hinsichtlich Vollständigkeit, Formatierung oder Korrektheit die Flexibilität des Datenimportmoduls einschränkt, sind die Mindestvoraussetzungen so gering wie nur möglich gehalten.
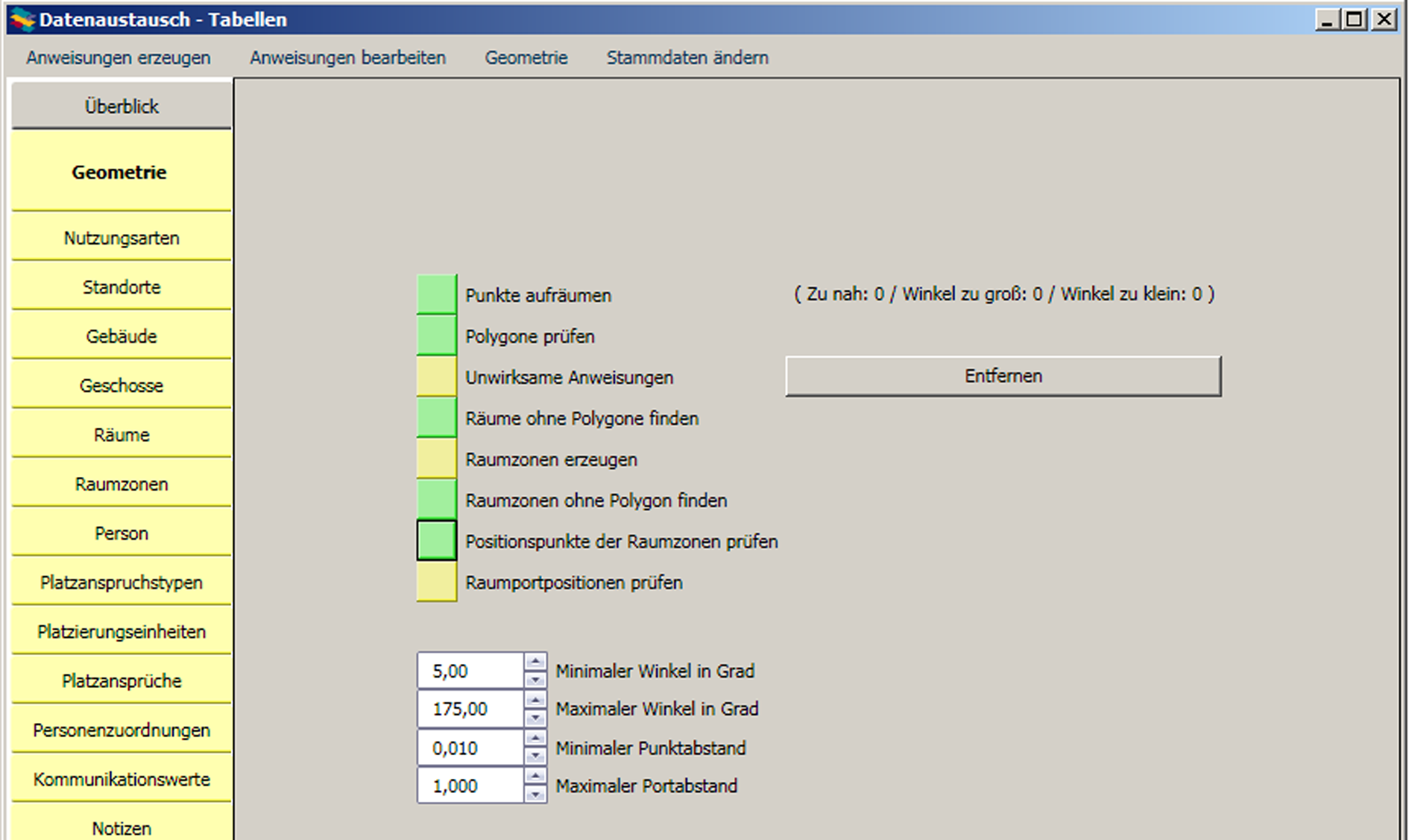
Die verschiedenen Prüfungen und Automatisierungen haben jeweils Voraussetzungen, die erfüllt sein müssen. Deshalb erfolgt die Verifizierung der Daten in der hier vorgestellten Reihenfolge. Die Überprüfung und Vervollständigung der Anweisungen ist umfangreich und komplex. Sie ist aber – im Erfolgsfall –automatisch.
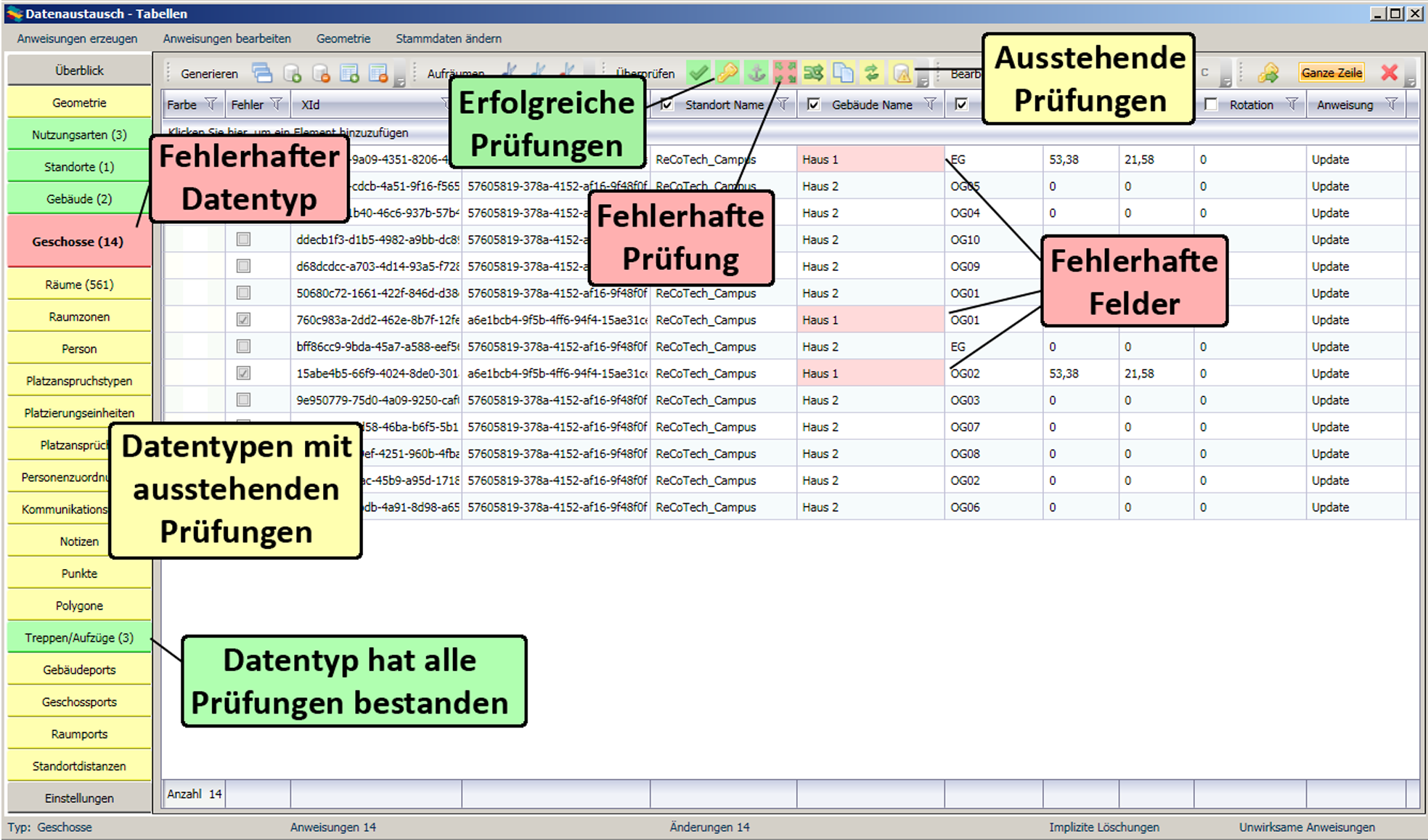
Sollten dabei Fehler oder Warnungen auftauchen, werden die entsprechenden Datensätze in der GUI hervorgehoben. Die Fehlerart wird durch Färbung des entsprechenden Überprüfungsbuttons angezeigt.
Es ist nicht notwendig, dass der Benutzer die Reihenfolge der Prüfungen kennt oder versteht. Sie werden hier nur der Vollständigkeit halber vorgestellt.
|
|
Feldtypen |
|
Im Datenimportmodul gibt es fünf verschiedene Kategorien von Feldern:
Alle Felder (selbst die Zahlfelder) des Datenimportmoduls sind vom Typ String damit erst mal jeder denkbare Wert eingegeben werden kann. |
|
Da die Dateneingabe flexibel sein soll und die Datensätze Redundanzen enthalten, soll es möglich sein, bei der Dateneingabe Felder leer zu lassen. Ein leerer String ist aber nur in Ausnahmefällen ein korrekter Wert. In den meisten Fällen ist es eine Datenlücke, die gefüllt werden muss. Deshalb müssen im ersten Schritt der Bearbeitung alle leeren Felder mit Werten gefüllt werden.
Es gibt fünf mögliche Gründe warum ein Feld zu diesem Zeitpunkt leer sein kann:
Die Autowerte sind insbesondere für Referenzen und Verweise sinnvoll. Die meisten Eingabedaten werden entweder die ID- oder die Namensdarstellung von Objektbeziehungen verwenden und dementsprechend die anderen Felder leer lassen. Das implementierte Verfahren unterscheidet nicht zwischen diesen zwei Formaten. Ohne Rückfrage wird jede beliebige Mischung mit beliebigen Lücken akzeptiert.
Um zwischen den fünf Interpretationen zu unterscheiden, existieren spezielle Strings, die für diese Interpretationen stehen. Im ersten Schritt der Bearbeitung müssen alle leeren Felder entweder durch einen Wert oder einen dieser Spezialstrings ersetzt werden. Um jedoch keine Formatvorgaben zu machen, sind diese Spezialstrings vom Benutzer definierbar. Die Strings gelten als Sonderzeichen und werden in den Feldern, in denen sie auftauchen können, immer interpretiert. Sie können dort also nicht als ihr buchstabengetreuer Wert verwendet werden.
Die Ersetzung leerer Felder durch syntaktisch korrekte Werte kann hier angestoßen werden:
![]()
Mit welchen Werten leere Felder gefüllt werden, ist vom Typ des Feldes abhängig. Die Default-Werte für die einzelnen Feldtypen sind, wie auch die Spezialstrings selbst, im Reiter Einstellungen konfigurierbar. Im gleichen Reiter befinden sich auch die Einstellungen für die wahr/falsch Angaben, die Anweisungsarten und die Konfiguration des Zahlformats.
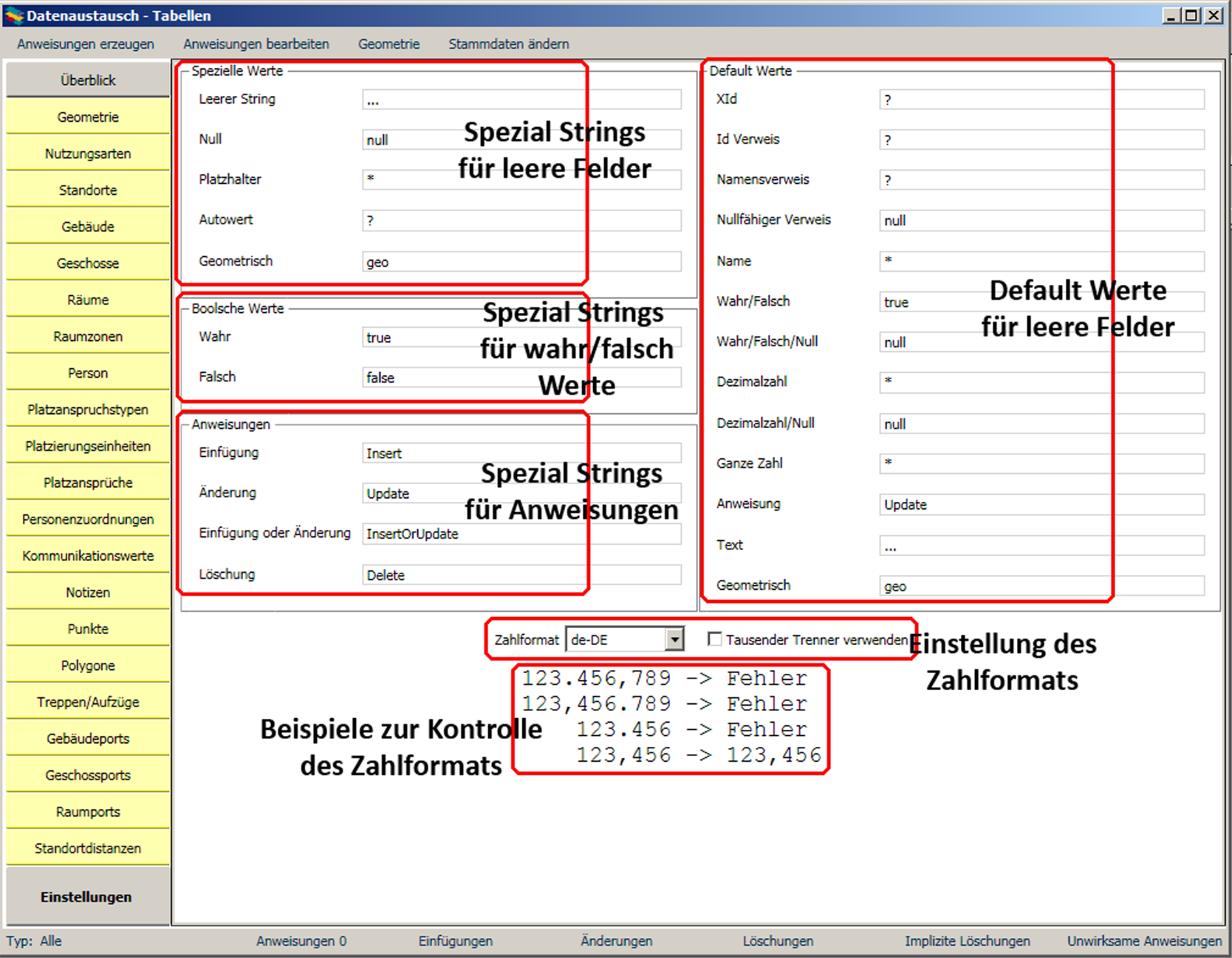
Im Gegensatz zu den Sonderstrings auf der linken Seite und den Zahlformat-Angaben lassen sich die Default-Werte nicht in Importprofilen definieren. In diesen wird stattdessen für jede Spalte der Default-Wert gesondert angegeben.
Dieser Schritt ist abgeschlossen, wenn es keine leeren Felder mehr gibt.
|
|
Zum Unterschied von Wildcards und Autowerten |
|
Wildcards und Autowerte haben gemeinsam, dass sie im Laufe der Verarbeitung durch explizite Werte ersetzt werden können und müssen. Dabei kommen allerdings völlig verschiedene Algorithmen zum Einsatz. Wildcards werden einfach durch den Wert ersetzt, den das entsprechende Feld des betreffenden recotech-Objektes gegenwärtig in den Stammdaten hat. Dementsprechend sind sie nur in Änderungs- und Löschanweisungen überhaupt sinnvoll. Die Ersetzung von Wildcards erfordert also lediglich, dass die Anweisung insoweit qualifiziert und überprüft ist, dass das gemeinte recotech-Objekt in den Stammdaten identifiziert werden kann. Die Ersetzung der Wildcard kann dann nicht fehlschlagen und zu einem früheren Zeitpunkt der Verarbeitung erfolgen als die Ersetzung der Autowerte. Insbesondere dienen die dabei eingesetzten Werte als Grundlage für die Ermittlung der Autowerte. Autowerte stehen oft in Feldern, die selbst zur Identifikation des recotech-Objektes herangezogen werden. Es ist algorithmisch daher nicht ganz einfach zu unterscheiden, ob ein Wert geändert werden soll, oder ob ein ganz anderes Objekt gemeint ist. Außerdem werden sie anhand aller zur Verfügung stehender Informationen, d. h. der Stammdaten sowie aller geplanten und noch unter Bearbeitung stehenden Anweisungen, ermittelt. Diese Anweisungen können zum Zeitpunkt der Autowertersetzung noch versteckte Fehler im Zusammenhang mit eben diesen Autowerten enthalten. Sie können und sollten also auch in Feldern stehen, deren Werte indirekten Änderungen unterliegen. Damit muss der Benutzer die genauen Konsequenzen dieser Änderungen nicht selbst antizipieren. Ein Beispiel zur Verdeutlichung: Die Ersetzung der Autowerte erfolgt durch einen iterativen Algorithmus, der sowohl die Autowerte ersetzt als auch die Menge der Verweise und Referenzen eines Datensatzes auf ihre Konsistenz überprüft. Der für den Benutzer entscheidende Punkt ist folgender: Felder mit Autowerten dürfen von den Stammdaten abweichen, wenn andere Änderungen dies erfordern. Felder mit Wildcards dürfen dies nicht. Insbesondere bedeutet dies, dass in Einfüge-Anweisungen Autowerte aber keine Wildcards zulässig sind. Dementsprechend schränkt eine Wildcard die Menge der möglichen konsistenten Interpretationen ein, ein Autowert tut dies nicht. |
|
Unter korrekter Syntax sind hier alle Prüfungen zusammengefasst, die auf einem einzelnen Feld ohne Berücksichtigung anderer Felder oder ganzer Datensätze ausgeführt werden können.
Für alle Felder wird überprüft, ob sie einen Spezialstring enthalten, der für dieses Feld grundsätzlich nicht erlaubt ist (z. B. Wildcards in einem XId Feld) oder ob der Wert nicht interpretierbar ist. Letzteres betrifft Felder, deren Inhalt (alle Felder sind vom Typ String!) eine Zahl, ein Boolean oder einen Anweisungstyp darstellen soll und entsprechend geparst wird. Leere Felder sind immer syntaktisch falsch.
|
|
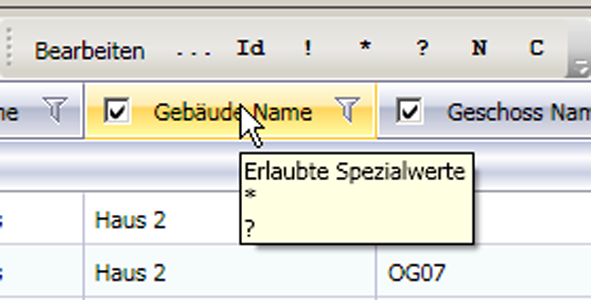
Welche speziellen Werte statt einer leeren Zeichenkette in welchem Feld syntaktisch erlaubt sind, wird durch den Tooltip der Spaltenköpfe in den Importtabellen angezeigt. |
|
Die Darstellung von Zahlen in Bezug auf Dezimaltrennzeichen und/oder Tausendertrennzeichen ist in den Einstellungen konfigurierbar und muss in Importprofilen angegeben werden. Die Angabe des Zahlformats erfolgt in Form eines Länderkürzels (de-DE, en-US etc.) und einem Boolean für die Verwendung des Tausendertrennzeichens. Diese Angaben bestimmen den verwendeten Parser und sie gelten für alle Objekttypen/Tabellen gleichermaßen.
|
|
Tausender Trennzeichen |
|
Es wird dringend empfohlen, Tausendertrennzeichen nur dann zuzulassen, wenn dies absolut notwendig ist, insbesondere beim Einsatz von CSV-Dateien, die zu irgendeinem Zeitpunkt mit Excel bearbeitet wurden. Im Zahlformat de-DE wird ansonsten "123.45" ohne Warnung oder Fehler als 12345 interpretiert, obwohl wahrscheinlich 123,45 gemeint war. |
|
Die Darstellung von booleschen Werten kann der Benutzer ebenfalls selbst konfigurieren. Alle Felder, in denen boolesche Werte erwartet werden, werden dann entsprechend interpretiert.
Alle Prüfungen, die mehr als nur das einzelne Feld betrachten finden hier noch nicht statt. Zum Beispiel sind Wildcards in Einfügungen generell unsinnig, unabhängig davon ob ein Feld prinzipiell Wildcards erlaubt.
Die Syntaxprüfung kann hier angestoßen werden:
![]()
Dieser Schritt ist abgeschlossen, wenn alle Felder im beschriebenen Sinn syntaktisch korrekte Werte enthalten.
|
|
Fehlerdarstellung |
|
Jede Prüfung kann durch einen Knopf in der Objekt-Werkzeugleiste angestoßen werden. Diese Knöpfe dienen gleichzeitig der Fehlerdarstellung: Bei Erfolg einer Prüfung wird der entsprechende Knopf grün, bei einem Fehler rot. Gelbe Prüfungsknöpfe zeigen an, dass es in dieser Tabelle mindestens ein Datenimportobjekt gibt, für das diese Prüfung noch nicht durchgeführt wurde, oder für das seit der letzten Durchführung erfolgte Änderungen eine neue Überprüfung notwendig machen. Im Fehlerfall werden alle fehlerhaften Felder rot hinterlegt. Zusätzlich wird der Fehlerstatus in einer eigenen Spalte angezeigt, so dass nach fehlerhaften Datensätzen sortiert und gefiltert werden kann. Um evtl. Fehler zu beheben, ist es wichtig zu verstehen, was die einzelnen Prüfungen kontrollieren und dementsprechend welche Arten von Fehlern sie anzeigen. Die Färbung der Reiter auf der linken Seite zeigt den Prüfungsstatus aller Anweisungen des entsprechenden Objekttyps an. Grün bedeutet, dass alle Datenimportobjekte dieses Typs alle Prüfungen bestanden haben. Rot bedeutet, dass es mindestens eines gibt, für das eine Prüfung fehlschlug. Gelb bedeutet, dass es mindestens ein Objekt gibt, für das mindestens eine Prüfung noch oder wieder aussteht.
|
|
Die XIds stellen sowohl den Bezug der Daten zu externen Systemen als auch die logische Verknüpfung der Datenimportobjekte untereinander und mit den recotech-Objekten in den Stammdaten dar.
Sie sollten nach Möglichkeit immer mit angegeben werden. Sollten in den Quelldaten keine solchen IDs vorliegen (wie z. B. bei aus Telefonlisten erstellten Personallisten), ist trotzdem sowohl der Import als auch die Pflege von Daten möglich, allerdings nur soweit die Identifizierung inhaltlich möglich ist.
Jeder beliebige String ist als XId erlaubt, es wird aber ausdrücklich davon abgeraten, in diese XId inhaltliche Informationen zu kodieren.
|
|
Pflege der XIds |
|
Die inhaltliche Identifikation von Objekten ist stark von kontextuellen Namenseindeutigkeiten der Objekte abhängig und möglicherweise mit einem gewissen Maß an manuellem Aufwand verbunden. Es wird dennoch dringend davon abgeraten, Werte als XIds zu verwenden, die nicht von einem anderen System als IDs gepflegt werden. Insbesondere ist die Verwendung von fortlaufenden Nummern in sich ändernden Excel-Tabellen fast eine Garantie für zukünftige Dateninkonsistenz. |
|
Falls das externe System keine IDs zur Verfügung stellt, müssen sie beim ersten Import der Daten erzeugt werden. Zu diesem Zweck dürfen die XId Felder im Fall einer Einfüge-Anweisung einen Autowert enthalten. Es wird dann eine neue GUID vergeben.
Unter Umständen ist es notwendig oder wünschenswert, auch bei Anpassungen Eingabedaten ohne XId zu verwenden. Wenn z. B. nur die Größe von Raumzonen geändert werden soll, ließe sich der zu ändernde Datensatz auch anhand der restlichen Attribute finden. Im Fall der Nachfragedaten ist es denkbar, dass sie aus verschiedenen Excel-Tabellen bestehen, die immer wieder aus Telefonlisten, Umfragen und sonstigen nicht systematischen Quellen neu erstellt werden, die dann eingepflegt werden sollen.
Um diesen Anwendungsfall abzudecken, wird die Möglichkeit geboten, auch bei Änderungs- und Löschanweisungen im XId-Feld den Autowert zuzulassen. In diesem Fall sind die Spalten bzw. Attribute anzugeben, deren Werte zur Identifizierung des betreffenden Objektes herangezogen werden sollen. Dies sollten offensichtlich nur solche sein, deren Werte sich nicht ändern.
Diese Angabe und die darauf folgende Suche geschehen vollständig auf Verantwortung des Benutzers. Es gibt keine Möglichkeit, sie zu überprüfen. Sollten von Änderungen betroffene Werte zur Identifizierung von Objekten verwendet werden, kann die Identifizierung scheitern oder fehlerhaft ausfallen. Das gleiche gilt für die Objektidentifizierung per XId. Gerade deshalb sollten nur XIds verwendet werden, die tatsächlich von einem anderen System als IDs gepflegt werden.
Bei der inhaltlichen Suche nach dem betreffenden recotech-Objekt filtert jede identifizierende Spalte die vorhandenen Stammdatenobjekte. Bleibt dabei genau eines übrig, wird dessen XId gesetzt. Wenn mehrere oder keine Kandidaten übrig bleiben, kann keine Ersetzung vorgenommen werden und die kombinierte XId- und Anweisung-Prüfung wird diesen Datensatz als fehlerhaft ausweisen. Nur falls die Anweisung als Einfügung/Änderung gesetzt ist, wird eine neue GUID als XId vergeben.
Erfolglose Suchen nach einer passenden XId gelten weder als Fehler noch als Warnung und werden nicht ausgewiesen. Sie treten erst in der entsprechenden Prüfung auf. Dies gilt gleichermaßen für die anderen reinen Ersetzungs- und Vervollständigungsfunktionen.
Die Ersetzung der XIds kann hier angestoßen werden:
![]()
Ob eine Spalte identifizierend ist, kann über die Checkbox in den Spaltenköpfen angepasst werden:

Umgekehrt kann ein Autowert in der Anweisungsspalte durch Interpretation einer explizit gesetzten XId aufgelöst werden: Wenn die XId in den Stammdaten nicht existiert, muss es sich um eine Einfüge-Anweisung handeln. Wenn sie existiert, kann es sich bei der Anweisung um eine Löschung oder Änderung (möglicherweise auch eine, die tatsächlich nichts ändert) handeln. Die Default-Interpretation für die automatische Ersetzung ist Änderung. Eine Löschung sollte vom Benutzer oder den Quelldaten explizit befohlen werden.
Im Anweisungsfeld ist neben dem Autowert noch der Spezialstring für Einfügung oder Änderung ersetzungsbedürftig. Je nachdem ob die XId in den Stammdaten existiert oder nicht, wird diese Anweisung als Änderung eines bestehenden Objektes oder als Einfügung eines neuen Objektes behandelt und der Wert des Anweisungsfeldes dementsprechend ersetzt.
|
|
XId und Anweisung einfach gemacht |
|
Für die Behandlung von XId und Anweisung ist folgende einfache Regel sinnvoll: |
|
Die Ersetzung in den Anweisungsfeldern kann hier angestoßen werden:
![]()
Die Ersetzung der XId und der Anweisung setzt eine erfolgreiche Syntax Prüfung voraus.
|
|
Implizite Prüfungen und Prüfungsstatus |
|
Eine ähnliche Abhängigkeit von bestimmten Prüfungen gilt für so gut wie alle Aktionen, insbesondere auch für die Prüfungen selbst. Die meisten setzen die erfolgreiche Durchführung einer oder mehrerer anderer Prüfungen voraus. Teilweise sind das sogar Prüfungen in anderen Objekten. Dadurch ergeben sich teilweise sehr tiefe rekursive Prüfungsketten. Sollten vorausgesetzte Prüfungen noch nicht ausgeführt worden sein, geschieht dies implizit, wann immer es notwendig ist. Das Programm verhält sich so als würden alle notwendigen Knöpfe in der richtigen Reihenfolge gedrückt. Das kann dazu führen, dass eine Aktion gar nicht durchgeführt wird und das Programm stattdessen einen Fehler an einer ganz anderen und vielleicht unerwarteten Stelle anzeigt. Wenn im Folgenden auf eine Prüfung als Voraussetzung für eine bestimmte Aktion hingewiesen wird, ist damit immer dieses Verhalten gemeint. Umgekehrt kann jede Änderung in den Datenaustauschobjekten erfolgreich ausgeführte Prüfungen ungültig machen. Dabei wird nicht unterschieden, ob eine Änderung durch den Benutzer oder durch einen Automatismus erfolgt ist. Alle Datenimportobjekte haben dafür einen internen Prüfungsstatus, der sehr freigiebig zurückgesetzt wird. |
|
Die beiden Felder XId und Anweisung können nur gemeinsam überprüft werden. Die offensichtliche Fehlerquelle ist der Fall in dem beide einen Autowert haben und sich dementsprechend keiner aus dem anderen ergibt. Wenn beide gesetzt sind, dürfen sie sich nicht widersprechen: eine Einfüge-Anweisung darf keine XId haben, die in den Stammdaten schon existiert und Änderungs- und Löschanweisungen müssen eine XId haben, die in den Stammdaten vorhanden ist.
Die XId und Anweisung Überprüfung kann hier angestoßen werden:
![]()
Diese Prüfung setzt die erfolgreiche Syntax Prüfung voraus.
Für Punkte und Polygone werden keine XIds gepflegt. Raumzonen haben in recotech höchstens ein Polygon, so dass ihre Polygonpunkte in der recotech-Datenbank direkt die Raumzonen referenzieren. Der Einfachheit halber soll aber die Behandlung von Raum- und Raumzonenpolygonen im Datenimportmodul möglichst gleich sein, so dass die Beziehung von Punkt zu Raumzone hier auch über ein Polygonobjekt erstellt wird. Das Datenimportmodul erlaubt prinzipiell auch Datenstrukturen, in denen die Punkte direkt auf Räume bzw. Raumzonen verweisen. In diesem Fall sollten die XIds der Räume bzw. Raumzonen für die PolygonId verwendet werden.
Kommunikationswerte und Standortdistanzen haben ebenfalls keine XId. Für diese ist aber auch keine Unterscheidung zwischen Einfügung, Löschung und Änderung nötig. Beide Objekte qualifizieren Beziehungen, die implizit immer vorhanden sind. Alle Anweisungen sind also effektiv Änderungen. Einen Wert auf 0 bzw. auf unendlich zu setzen, führt technisch dazu, dass das entsprechende recotech-Objekt gelöscht wird. Für Kommunikationsbeziehungen und Standortdistanzen entfällt dieser Schritt also ebenfalls. Kommunikationsbeziehungen und Standortdistanzen, deren Platzierungseinheiten bzw. Standorte gelöscht werden, werden automatisch ebenfalls gelöscht, ohne dass eine explizite Anweisung erforderlich ist.
Die letzte Ausnahme sind die Zuordnungen von Personen zu Platzansprüchen. Diese qualifizieren keine immer implizit bestehende Relation, sondern stellen diese durch ihre bloße Existenz erst her. Es muss also möglich sein, diese Objekte zu löschen. Damit muss es ein Anweisungsfeld geben, das auch den Autowert als Wert erlaubt. An einem solchen Objekt kann allerdings nichts geändert werden. Alle Autowerte werden also als Einfügung interpretiert.
Dieser Schritt ist abgeschlossen, wenn alle Anweisungen eine explizite XId und einen definierten Anweisungstyp haben (sofern diese Felder vorhanden sind) und sich die beiden Werte nicht widersprechen.
Als Vorbereitung für die Überprüfung der Referenz- und Verweisfelder müssen in diesem Schritt alle Wildcards durch explizite Werte ersetzt werden. Für alle Objekte mit einer XId, die in den Stammdaten existiert, ist dies automatisch möglich. Nach dem vorherigen Schritt sind alle Anweisungen mit neuen XIds Einfügungen. Eventuelle Wildcards muss der Benutzer selbst durch konkrete Werte (oder Autowerte, wo dies möglich ist) ersetzen.
Bei Objekten ohne XId ist die automatische Ersetzung von Wildcards nicht möglich: Punkte und Polygone sind ohnehin immer Einfügungen, in denen keine Wildcards erlaubt sind. Die Objekte für Kommunikationswerte, Standortdistanzen und Personenzuordnungen werden über ihre Referenz- und Verweisfelder überhaupt erst identifiziert. Eventuelle Lücken in den Referenz- und Verweisfeldern in diesen Objekten müssen dementsprechend mit Autowerten und nicht mit Wildcards gefüllt sein. Wildcards in diesen Objekten werden als syntaktisch falsch definiert und damit schon im ersten Schritt ausgeschlossen.
Die Ersetzung von Wildcards kann hier angestoßen werden:
![]()
Diese Funktion setzt die erfolgreiche Prüfung der XId und der Anweisung voraus.
Die Ersetzung der Wildcards korrespondiert mit der dritten Prüfung, der des Stammdatenbezugs. Dass für alle Datenimportobjekte, die Änderungen oder Löschungen darstellen, ein eindeutiges recotech -Objekt in den Stammdaten existiert, ist bereits im letzten Schritt verifiziert worden. Hier wird darüber hinaus verifiziert, dass die Löschanweisungen die zu löschenden recotech-Objekte auch inhaltlich korrekt darstellen.
Die Überprüfung des Stammdatenbezugs kann hier angestoßen werden:
![]()
Sie setzt die erfolgreiche Prüfung der XId und der Anweisung voraus.
Dieser Schritt ist abgeschlossen, wenn es keine Wildcards und keine (unzulässigen) Abweichungen von den Stammdaten in Löschanweisungen mehr gibt.
|
|
Löschungen und Stammdatenbezug |
|
Für eine Löschung ist technisch gesehen nur die XId relevant. Das Programm löscht den einen Raum mit der XId 'xyz', was auch immer sich dahinter verbirgt. Der menschliche Benutzer liest, versteht und meint die entsprechende Anweisung aber z. B. als Löschung des Raumes 4711 im Erdgeschoss des Gebäudes Müllerstr. 5. Abweichungen in der Darstellung in Löschanweisungen von den per XId referenzierten recotech-Objekten sind streng gesehen keine Fehler, weil die Verarbeitung trotzdem erfolgreich weiterlaufen könnte. Im Interesse der Datensicherheit werden sie trotzdem nicht nur als Warnungen ausgegeben, sondern unterbrechen wie andere Fehler den Verarbeitungsprozess und müssen bereinigt werden. Die Bereinigung bzw. Vermeidung solcher Fehler ist mithilfe der Wildcards und Autowerte relativ einfach. Nach deren automatischer Ersetzung hat der Benutzer die Garantie, dass auch tatsächlich das gelöscht wird, was er glaubt zu löschen. |
|
|
|
Referenzen, Verweise, Stammdatenbezug und Reihenfolge |
|
In diesem Zusammenhang kann auf ein technisches Detail hingewiesen werden, das auch zum besseren Verständnis des Unterschieds zwischen Autowerten und Wildcards sowie zwischen Verweis- und Referenzfeldern beiträgt. Dazu zunächst ein Beispiel: Der Büroraum 4711 soll in zwei kleinere Räume geteilt werden. Das bedeutet, ihn zu löschen und stattdessen zwei neue Räume anzulegen. Bei korrekter Angabe seiner XId können in allen anderen Feldern (außer der Anweisung) Wildcards stehen. Diese werden ersetzt und der Benutzer sieht, was passieren wird. Zunächst scheint vielleicht offensichtlich, dass in der Löschung nur der alte und in den Einfügungen nur der neue Name korrekt sein sollte. Damit würde aber der Benutzer gezwungen, die Reihenfolge der Anweisungen zu beachten oder vielleicht sogar konfigurieren zu müssen. Darüber hinaus gibt es folgendes Problem: Das zugrunde liegende recotech-Objekt hat nur eine Referenz auf ein Nutzungsartobjekt. Der Name an diesem Objekt kann damit jederzeit korrekt aufgelöst werden. Das Datenimportobjekt hat dementsprechend das Referenzfeld "Nutzungsart XId", darüber hinaus aber auch das Verweisfeld "Nutzungsart Name". Noch deutlicher wird dies anhand der Verweisfelder "Geschoss Name", "Gebäude Name" und "Standort Name". Deren Werte werden in den recotech-Objekten über die Referenzkette Raum → Geschoss →Gebäude →Standort aufgelöst. Letztlich herrscht an dieser Stelle ein logischer Zirkel: die inhaltliche Identität eines Objektes, die hier unter Verdacht steht, hängt entscheidend von den Beziehungen zu anderen Objekten ab. Und die korrekte Analyse dieser Beziehung ist wiederum abhängig von der gesicherten Identität des Objektes. Deshalb können in der Prüfung des Stammdatenbezugs nur die Felder/Attribute verglichen werden, die an den recotech-Objekten direkt vorhanden sind. Konkret bedeutet dies, dass alle Felder, die Namen anderer Objekte enthalten, von dieser Kontrolle ausgeschlossen sind. Die Kontrolle ignoriert also tatsächlich genau die Felder, über die ein menschlicher Benutzer die inhaltliche Identifizierung vornimmt, deren Prüfung der ganze Sinn der Stammdatenbezugsprüfung sein sollte. |
|
Die Überprüfung der Referenz- und Verweisfelder ist in zwei Schritte aufgeteilt. Im ersten wird sichergestellt, dass die angegebenen Werte überhaupt existieren. Felder mit Auto- und Geowerten enthalten (noch) keine Informationen und sind immer gültig. Man beachte aber, dass spätere Ersetzungen (auch durch Automatismen) die erneute Gültigkeitsprüfung der dann explizit gesetzten Werte erzwingen.
Die Gültigkeit einer expliziten Referenz bzw. Anweisung ist wie folgt definiert:
|
|
Einfügung/Änderung |
Löschung |
|
Referenz |
Das referenzierte Objekt wird nach der Ausführung aller Anweisungen existieren. |
Das referenzierte Objekt existiert schon jetzt. |
|
Verweis |
Mindestens ein Objekt des entsprechenden Typs wird nach der Ausführung aller Anweisungen diesen Wert haben. |
Mindestens ein Objekt des entsprechenden Typs hat diesen Wert jetzt schon und mindestens ein Objekt des entsprechenden Typs wird nach der Ausführung aller Anweisungen diesen Wert haben. Das müssen nicht dieselben Objekte sein! Oder Mindestens ein Objekt des entsprechenden Typs hat diesen Wert jetzt und wird ebenfalls gelöscht. |
Die Gültigkeitsprüfung der Referenzen und Verweise kann hier angestoßen werden:
![]()
Dieser Schritt ist abgeschlossen, wenn alle Referenzen und Verweise in diesem Sinne gültig sind.
|
|
Objekthierarchie und Reihenfolge |
|
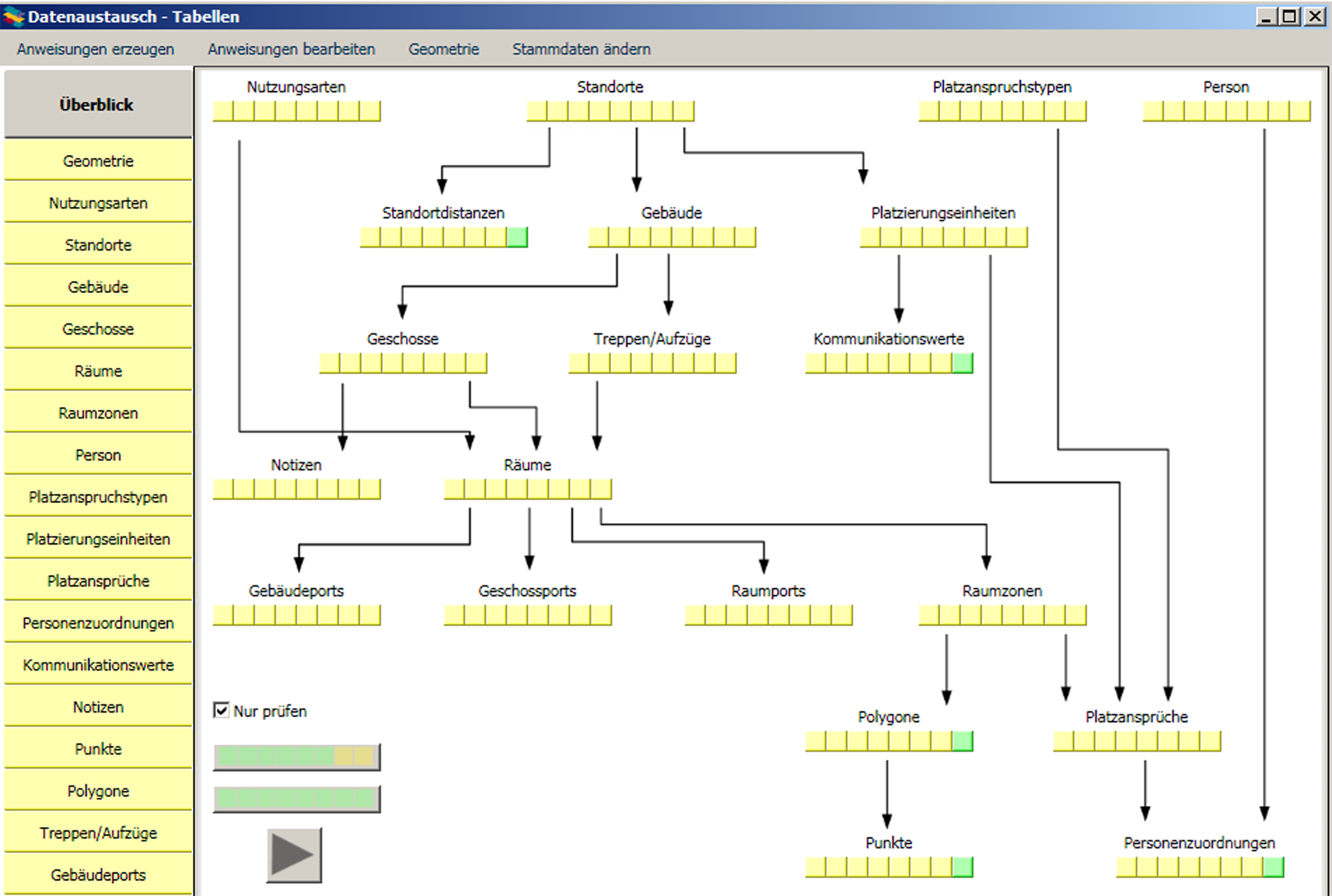
Um beurteilen zu können, ob es nach der Ausführung aller Anweisungen Objekte mit einer bestimmten XId oder mit einem bestimmten Wert geben wird, ist es notwendig, dass alle in Frage kommenden Datenimportobjekte des referenzierten Typs vollständig gefüllt und vor allem fehlerfrei sind. Welche Objekte für die Verweisgültigkeitsprüfung welcher anderen relevant sind, ist durch die Pfeile im Überblicksreiter symbolisch dargestellt. Diese Reihenfolge zu kennen ist nicht notwendig.
Die Prüfung der Verweisgültigkeit an den Platzansprüchen ist z. B. rekursiv abhängig von allen Fehlerprüfungen in den neun übergeordneten Objektarten. Diese 54 Prüfungen würden bei Bedarf automatisch durchgeführt. Die je acht gelben Felder unter den Typbezeichnungen stellen die sechs Fehler- und die zwei Warnungsprüfungen dar. Der Status der Prüfungen ist farbkodiert (grün: Erfolg, rot/orange: Misserfolg, gelb: noch/wieder auszuführen). Es sind Knöpfe, über die die entsprechenden Prüfungen auch von hier angestoßen werden können. An dieser zentralen Stelle ist es auch möglich, durch Deaktivieren der Checkbox "Nur prüfen" von hier die kombinierten Vervollständigungs- und Überprüfungsalgorithmen anzustoßen. Hier wird auch ein im Importprofil definiertes Komplettverarbeitungsmakro angestoßen. Im Erfolgsfall färben sich alle Knöpfe und Reiter von oben nach unten und von links nach rechts grün. |
|
Im vorherigen Schritt wurde die Gültigkeit (im oben definierten Sinn) jedes einzelnen Verweis- und Referenzfeldes sichergestellt. Dies garantiert aber noch nicht, dass sich diese Angaben nicht widersprechen. Der einfachste Widerspruch ist ein Konflikt zwischen der XId und dem Namen des Objektes, auf das Bezug genommen wird. Die Gültigkeitsprüfung mag erfolgreich verifiziert haben, dass es z. B. einen Raum mit der XId xyz gibt und auch dass es mindestens einen Raum mit dem Namen 4711 gibt. Ob aber der Raum mit der XId xyz den Namen 4711 trägt, wurde noch nicht getestet.
In diesem einfachen Fall wäre diese Prüfung im obigen Schritt ebenfalls möglich gewesen. Es gibt aber kompliziertere Zusammenhänge, deren Analyse deutlich aufwändiger ist und teilweise erfordert, dass manche Autowerte in Referenz- und Verweisfeldern noch während der Analyse Schritt für Schritt ersetzt werden. Damit dieser Algorithmus nicht unnötig angestoßen wird, werden mit der Überprüfung der Gültigkeit zunächst die Minimalvoraussetzungen für seinen Erfolg verifiziert.
|
|
Konsistenzprüfung ändert die Importobjekte |
|
Die Konsistenzprüfung der Verweise und Referenzen weicht in einem wichtigen Punkt von den anderen Prüfungen ab: sie kann und muss Datensätze verändern. Das liegt daran, dass beliebige Lücken in den Datensätzen erlaubt und die Darstellungen von Objektbeziehungen zwischen Datenimportobjekten hochgradig redundant sind und sich untereinander bedingen. |
|
Der Algorithmus zur Vervollständigung und Überprüfung der Objektbeziehungen (also der Referenzen und Verweise) arbeitet mit den Informationen, die er vorfindet, welche auch immer das sind.
Jedes Feld mit Informationen schränkt die Menge der möglichen Werte ein. Im Falle eines Referenzfeldes auf eins. Sobald die Menge der möglichen Werte für ein Feld mit Autowert nur noch ein Element enthält, wird dieser Wert gesetzt und kann in Folge für weitere Einschränkungen anderer Wertemengen verwendet werden.
Dieser Prozess terminiert in einem der folgenden Fälle:
Nur im ersten Fall ist die Prüfung bestanden und evtl. Autowerte werden ersetzt. In den anderen beiden Fällen ist die Prüfung fehlgeschlagen, alle während der Prüfung vorgenommenen Ersetzungen von Autowerten werden rückgängig gemacht und die problematischen Felder werden eingefärbt.
In Feldern mit Autowerten gilt: Rot bedeutet, dass kein möglicher Wert übrig blieb. Orange deutet an, dass mehrere übrig blieben. Auch wenn letzteres den weiteren Verarbeitungsprozess blockiert, wird dennoch die ansonsten für Warnungen genutzte Farbe verwendet, weil Informationen nur unzureichend und nicht direkt falsch sind.
Felder mit explizit gesetzten Werten werden im Problemfall immer rot. Das deutet an, dass die Menge der möglichen Werte den gesetzten nicht einschließt. Das kann daran liegen, dass sie leer ist oder auch nur, dass der gegebene Wert nicht einer der Elemente ist. In beiden Fällen liegt eine Dateninkonsistenz vor.
In jedem Fall werden nur die Felder hervorgehoben, in denen es ein Problem mit dem Inhalt des Feldes und den möglichen Werten gab.
Exemplarisch sind die Abhängigkeiten der Objektverweise am Raum in der folgenden Grafik dargestellt:
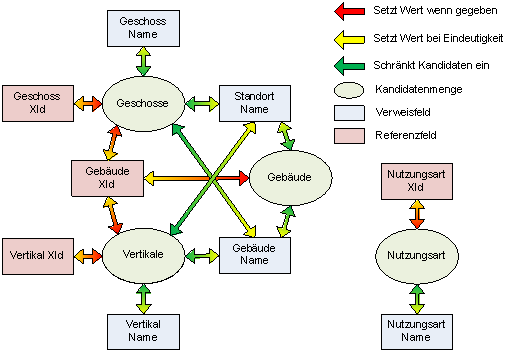
Eine ähnliche Grafik ließe sich für alle anderen Objekte erstellen. Generell gilt: Referenzen (Angabe einer XId) sind besser als Verweise (Angabe des Namens), weil erstere das entsprechende Objekt eindeutig identifizieren, während letztere nur die Menge der Kandidaten einschränken. Je mehr Namen global oder auch nur kontextuell eindeutig sind, desto wertvoller und informativer sind aber die Namensverweise.
recotech macht bei der Namensvergabe keinerlei Beschränkungen, im Extremfall könnten alle Objekte gleich heißen (es wird aber dringend geraten, zumindest auf kontextuelle Namenseindeutigkeit zu achten). Es werden also keine Vorgaben bezüglich Namenseindeutigkeit gemacht.
Jede in den Quelldaten bestehende Systematik bei der Namensvergabe lässt sich aber als Alternative zur Identifizierung mittels XId ausnutzen, auch wenn sie zufällig und nur partiell sein sollte. Dazu muss sie weder formal erfasst werden noch überhaupt bekannt sein; wenn sie besteht, wird der Algorithmus sie ausnutzen.
Die Ersetzung der Autowerte bzw. Prüfung der Objektverweise kann hier angestoßen werden:
![]()
![]()
Beide Knöpfe stoßen dieselbe Funktion an. Sie ist doppelt vorhanden, weil sie sowohl eine Prüfung als auch eine Vervollständigung darstellt und somit in beide Teile der Menüleiste gehört.
Dieser Schritt ist abgeschlossen, wenn es keine Autowerte mehr gibt und alle Objektverweise konsistent sind.
Die letzte Fehlerprüfung besteht in der Suche nach doppelten Anweisungen, d. h. Anweisungen, die sich auf das gleiche Objekt beziehen. Bei den Datentypen, deren Identität in recotech gepflegt wird, gilt, dass pro XId immer nur genau ein Datenimportobjekt existieren darf.
Für die Objekte, die eine Beziehung zwischen zwei Objekten herstellen oder qualifizieren (Kommunikationswerte, Standortdistanzen und Personenzuordnungen), darf es pro solchem Paar nur genau ein Datenimportobjekt geben.
Polygone und Punkte haben keine XId und ihre Identität wird nicht gepflegt. Datenimportobjekte vom Typ Polygon gelten bei gleicher PolygonId als doppelt. Solche vom Typ Punkt gelten als doppelt, wenn sie sowohl in der PolygonId als auch in der Nummer übereinstimmen.
In diesem Sinne doppelte Anweisungen sind im besten Fall redundant, wenn sie das Gleiche bewirken, also in allen Feldern identische Werte haben. Wenn sie sich irgendwo unterscheiden, stellen sie widersprüchliche Anweisungen dar. Da alle Anweisungen so zu verstehen sind, als würden sie gleichzeitig ausgeführt, gibt es keinen Grund, für ein Objekt mehrere Anweisungen zuzulassen. Alles, was mit oder an einem recotech-Objekt geschehen soll, lässt sich in einem Datenimportobjekt ausdrücken.
Der einfache Fall der doppelten und identischen Anweisungen lässt sich automatisch beheben, indem alle bis auf eine solche Anweisung entfernt werden. Im Fall widersprüchlicher Anweisungen muss der Benutzer sich für eine entscheiden. In diesem Fall werden alle solchen Anweisungen als Fehler rot markiert.
Die Prüfung auf doppelte Anweisungen lässt sich hier anstoßen:
![]()
Das automatische Entfernen aller bis auf einer exakt gleichen Anweisung hier:
![]()
Beide Aktionen setzen die erfolgreiche Prüfung der Referenzen und Verweise voraus.
Dieser Schritt ist abgeschlossen, wenn keine doppelten Anweisungen mehr existieren.
Die letzten beiden objektspezifischen Prüfungen sind optional. Ein negatives Ergebnis wird nur als Warnung angezeigt, verhindert die weitere Verarbeitung jedoch nicht.
Die erste optionale Prüfung besteht darin, die Datenimportobjekte hervorzuheben, deren Ausführung keine Auswirkung haben wird. Hauptsächlich sind das Änderungsanweisungen, welche den Zustand des gemeinten recotech-Objekts nicht verändern. Im Fall der Personenzuordnungen auch Einfügungen (es gibt bei diesen keine Änderungen) von Zuordnungen, die in den Stammdaten ohnehin bestehen.
Löschanweisungen gelten nie als unwirksame Änderung. Das gilt auch für den Fall von Löschanweisungen, die aufgrund logisch notwendiger Löschweitergaben anderer Löschungen im Prinzip redundant sind, weil die entsprechenden Objekte ohnehin gelöscht werden würden.
Die Überprüfung auf unwirksame Anweisungen kann hier angestoßen werden:
![]()
Das automatische Entfernen unwirksamer Anweisungen erfolgt hier:
![]()
Die entsprechende Funktion für die geometrischen Daten erfolgt allerdings im Reiter Geometrie, da Punkte und Polygone nur gemeinsam auf Unwirksamkeit analysiert werden können.
Das Entfernen unwirksamer Änderungen dient in erster Linie der Kontrolle. Insbesondere beim Abgleich mit einem vollständigen Datenbestand mag es von Interesse sein, genau welche Objekte sich in den beiden Datenbeständen wie unterscheiden.
|
|
Löschungen, Datenpflege und Datenabgleich |
|
Im Datenimportmodul ist es möglich, für alle bestehenden recotech-Objekte, für die es kein Datenimportobjekt gibt, eine Löschanweisung generieren zu lassen. Also alles zu löschen, was nicht noch mal erwähnt wurde. Wenn dies vor dem Entfernen der unwirksamen Anweisungen geschieht, hat man nachher eine vollständige Liste aller Unterschiede in den beiden Datenbeständen, ausgedrückt in einer Liste aller Einfügungen, Änderungen und Löschungen, die notwendig wären um die recotech-Stammdaten auf den Stand der Quelldaten zu bringen. Auf diese Art ist es möglich, die recotech-Stammdaten auf den Stand eines Quellsystems zu bringen, ohne in letzterem eine Löschungshistorie pflegen zu müssen. |
|
Die im vorherigen Schritt vorgenommene Bereinigung doppelter Anweisungen erfolgte rein syntaktisch. Selbst wenn alle Datenimportobjekte sich technisch gesehen auf unterschiedliche recotech-Objekte beziehen, kann es immer noch zu inhaltlichen Doubletten kommen. Doubletten sind Objekte in Datenstrukturen, die aufgrund von unterschiedlichen IDs zwar syntaktisch und datentechnisch unterscheidbar sind, aber genau gleiche Werte haben. Ob es tatsächlich zwei reale Objekte gibt, die in den hier erfassten Attributen identisch sind oder ob eigentlich das gleiche reale Objekt gemeint ist, kann kein Algorithmus entscheiden. Deshalb hat die Doubletten Prüfung nur den Status einer Warnung.
Die Überprüfung auf inhaltliche Doubletten kann hier angestoßen werden:
![]()
Inhaltliche Doubletten können auch automatisch bereinigt werden. Dabei wird folgendermaßen verfahren:
Zunächst wird eine vollständige Liste aller nach der Ausführung aller Anweisungen existierenden Objekte (in möglicherweise geänderter Version) erstellt. Die Objekte in dieser Liste werden anhand ihrer Attribute so gruppiert, dass alle Objekte in einer Gruppe die gleichen Werte haben. Alle Elemente in Gruppen mit mehr als einem Element stellen inhaltliche Doubletten dar.
Wenn sich in einer solchen Gruppe mindestens ein bestehendes recotech-Objekt befindet, werden alle Einfügungen in dieser Gruppe entfernt.
Enthält diese Gruppe kein bestehendes recotech-Objekt (d. h. es gibt keine Änderungsanweisung in dieser Gruppe), werden alle bis auf eine Einfügung (die ja alle gleich aussehen) entfernt.
Der einzige Fall, in dem die Doubletten Bereinigung scheitert ist der, dass zwei oder mehr bestehende Objekte nach der Ausführung aller Anweisungen gleiche Werte haben würden. In diesem Fall muss der Benutzer entscheiden, ob es tatsächlich zwei reale Objekte gibt, die in recotech gleich aussehen oder ob ein Fehler vorliegt.
Die automatische Bereinigung inhaltlicher Doubletten erfolgt hier:
![]()
Sowohl die Prüfung auf sowie die Bereinigung von Doubletten setzt die erfolgreiche Prüfung auf doppelte Anweisungen voraus. Die Prüfung auf unwirksame Anweisungen ist nicht notwendig.
Im Rahmen dieses Abschnitts wurden bereits die meisten Funktionen der Objekt Werkzeugleiste vorgestellt, so dass es sich anbietet, an dieser Stelle auch die restlichen zu beschreiben.
Diese Funktion erzeugt für jedes in den Stammdaten vorhandene recotech-Objekt des entsprechenden Typs ein Datenimportobjekt, das dem recotech-Objekt in allen Werten exakt entspricht und vom Anweisungstyp Änderung ist. Alle so erzeugten Anweisungen sind entweder unwirksam im Sinne der obigen Prüfung oder sogar doppelt bzw. fehlerhaft. Letzteres ist der Fall wenn andere Änderungen/Löschungen, die anhand der bestehenden Stammdaten erzeugten Namensverweise und XId Referenzen ungültig machen. Doppelte Anweisungen ergeben sich wenn vor der Ausführung dieser Funktion schon Änderungs- oder Löschanweisungen existieren.
Sie kann hier angestoßen werden:
![]()
Diese Funktion hat keine Voraussetzungen.
Diese Funktion bewirkt fast das Gleiche wie die vorherige mit dem Unterschied, dass sie keine doppelten Anweisungen generiert. Für jedes recotech-Objekt, für das es schon eine Anweisung gibt, wird keine neue erzeugt. Deshalb setzt diese Funktion die erfolgreiche Prüfung des Stammdatenbezugs voraus, die gegebenenfalls implizit durchgeführt wird. Auf diese Art erzeugte Anweisungen können aber immer noch fehlerhaft sein, da alle Namensverweise und Referenzen in der bestehenden Form generiert werden, ohne evtl. vorhandene Änderungen/Löschungen in den verwiesenen Objekten zu berücksichtigen.
Sie kann hier angestoßen werden:
![]()
Diese Funktion bewirkt wiederum fast das Gleiche wie die vorangegangene mit dem Unterschied, dass alle zum Zeitpunkt der Ausführung existierenden anderen Anweisungen berücksichtigt werden. Änderungen in referenzierten Objekten werden in den so erzeugten Datensätzen korrekt dargestellt. Löschungen von referenzierten Objekten können bei der Erzeugung impliziter Änderungen drei Effekte haben:
Die Erzeugung impliziter Änderungen setzt die erfolgreiche Ausführung aller Fehlerprüfungen für diesen Typ voraus, die gegebenenfalls implizit durchgeführt wird.
Sie kann hier angestoßen werden:
![]()
Diese Funktion erzeugt für jedes bestehende recotech-Objekt des entsprechenden Typs, für das es noch kein Datenimportobjekt gibt, eine Löschanweisung. Diese Funktion dient in erster Linie dem Abgleich mit einem kompletten Datenbestand. Unter der Annahme, dass dieser vollständig ist, aber keine Informationen darüber enthält, welche Objekte seit dem letzten Datenabgleich gelöscht wurden, können alle bestehenden aber nicht mehr erwähnten recotech-Objekte gelöscht werden.
Diese Funktion setzt die erfolgreiche Prüfung des Stammdatenbezugs voraus, die gegebenenfalls implizit durchgeführt wird und kann hier angestoßen werden:
![]()
Diese Funktion erzeugt für alle von Löschweitergabe betroffenen Objekte des entsprechenden Typs eine explizite Löschanweisung. Alle so erzeugten Anweisungen sind im Prinzip redundant. Die entsprechenden Objekte werden selbst dann gelöscht, wenn es keine explizite Anweisung dafür gibt. Sie gelten dennoch nicht als unwirksam im obigen Sinne, was gewissermaßen uneinheitlich ist. Der Benutzer soll aber die Möglichkeit haben, alle Prüfungen und Warnungen erfolgreich abzuschließen und die vollständige Liste aller bei Ausführung zu erwarteten Änderungen am Datenbestand zu sehen.
Die Erzeugung impliziter Löschungen setzt die erfolgreiche Ausführung aller Fehlerprüfungen für diesen Typ voraus, die gegebenenfalls implizit durchgeführt werden.
Sie kann hier angestoßen werden:
![]()
Manche Quellsysteme verfügen nicht über exportierbare IDs, verwenden aber beim Export in CSV-Dateien fortlaufende Nummern, um Verweise zwischen Objekten darzustellen. In den meisten Fällen können solche Verweise schon beim Einlesen der CSV-Dateien ausgewertet werden (siehe dazu: "Importmodul IV: Importprofil"). Falls das nicht möglich ist oder das entsprechende Importprofil nicht dahingehend konfiguriert ist, sollten solche fortlaufenden Nummern nicht als XId in die Stammdaten gelangen.
Die Nummer, die ein bestimmtes Objekt bekommt, kann und wird aller Wahrscheinlichkeit nach beim nächsten Export aus dieser Quelle eine andere sein. Die Durchnummerierung aller Objekte ist nur innerhalb des einen Exports für die Identifizierung ausreichend. Für den Abgleich mit den Stammdaten ist eine solche Nummerierung im besten Fall nutzlos, meistens schädlich.
Es ist möglich, solche Pseudo IDs vor der Ausführung der Anweisungen durch Autowerte zu ersetzen, die dann wieder wie oben beschrieben aufgelöst werden. Die entsprechende Funktion in der Objekt-Werkzeugleiste ersetzt nur die XId in den Datenimportobjekten des entsprechenden Typs. Die Referenzen auf andere Objekte bleiben erhalten. Um auch diese durch Autowerte zu ersetzen, kann entweder die in allen Tabellen vorhandene Massenverarbeitungsfunktion genutzt, oder über eine Funktion in der Menüleiste eine globale Ersetzung angestoßen werden.
Die entsprechenden Funktionen sind hier verfügbar:
![]()
|
|
Datenabgleich mit temporären IDs |
|
Auch wenn die Verwendung temporärer IDs als XIds zukünftige Dateninkonsistenz so gut wie garantiert, sind sie als Übergangslösung im Importprozess durchaus nützlich. Mit ihrer Hilfe können die Verweisfelder gesetzt werden. Und mit deren Hilfe ist es möglich, die temporären IDs durch sichere Referenzen zu ersetzen. Die temporären IDs bilden somit die Leiter, an der man hochsteigen kann, um sie von oben wegzustoßen. Das genaue Vorgehen ist wie folgt:
Dieses Verfahren wird nur dann erfolgreich sein, wenn die Verweisfelder den gleichen Informationsgehalt haben wie die Referenzfelder. Im Allgemeinen nur dann, wenn eine hinreichende kontextuelle Namenseindeutigkeit in den Daten vorherrscht. |
|
In den Importtabellen gibt es zwei Auswahlmodi: Ganze Zeilen und einzelne Zellen. Standardmäßig ist der Zeilenauswahlmodus aktiv. Für Copy/Paste-Aktionen, die nur einzelne Zellen oder Spalten betreffen, muss auf Zellenauswahl umgestellt werden.
Der entsprechende Knopf befindet sich hier:
![]()
Der letzte Knopf entfernt alle selektierten Zeilen. Er ist nur im Zeilenauswahlmodus aktiv. Man beachte, dass das Entfernen einer Zeile, d. h. eines Datenimportobjekts nicht etwa ein recotech-Objekt löscht. Nur die durch das Objekt kodierte Anweisung wird entfernt.
Wie an vielen Stellen bereits betont wurde, ist für den Erfolg des inhaltlichen Datenabgleichs (d. h. ohne XIds oder nur mit temporären IDs) die kontextuelle Eindeutigkeit der Verweise unerlässlich. Damit ist gemeint, dass innerhalb eines natürlichen Kontextes gewisse Attribute eindeutig sind. I.d.R. sind das die Namen der Objekte innerhalb des Kontextes ihres direkt übergeordneten Objektes (Raum Namen innerhalb eines Geschosses, Platzanspruch Namen innerhalb einer Platzierungseinheit etc.). Falls eine solche Eindeutigkeit gegeben ist, sind die Namensketten (z. B. Raum-, Geschoss-, Gebäude- und Standortname eines Raumes) einer XId logisch gleichwertig und im Gegensatz zur XId auch inhaltlich aussagekräftig. Diese Art kontextueller Namenseindeutigkeit wird im normalen recotech-Betrieb nicht forciert. Im Extremfall könnten alle Objekte gleich heißen. Auf Wunsch kann eine solche kontextuelle Eindeutigkeit beim Import aber durch das Hinzufügen von Nummernsuffixen hergestellt werden. Diese Funktion ist für Namen und insbesondere auch für Kommentare verfügbar. Kommentarfelder sind üblicherweise beliebig editierbar und können im Importmodul als identifizierendes Attribut verwendet werden.
Die entsprechenden Knöpfe befinden sich hier:
![]()
![]()
Die geometrischen Prüfungen und Vervollständigungen umfassen in der Regel Objekte mehrerer Typen (Raumzonen, Räume, Raumports, Polygone und Punkte). Deshalb sind sie in einem eigenen Reiter untergebracht. Sie sind wie die anderen Funktionen auch teilweise voneinander abhängig und werden bei Bedarf implizit durchgeführt. Allen ist gemeinsam, dass sie die Fehlerfreiheit im Sinne der oben aufgeführten Fehlerprüfungen aller Datenimportobjekte voraussetzen.
Das ist deutlich mehr als logisch notwendig, aber vom Arbeitsablauf leichter zu merken. Die geometrischen Prüfungen sind sozusagen der krönende Abschluss. Sie sind mit Abstand auch die aufwändigsten Prüfungen und es wäre Zeitverschwendung sie durchzuführen, bevor alle schnellen Prüfungen abgeschlossen sind.
Diese erste geometrische Prüfung säubert die Punkte und reduziert sie auf das geometrisch notwendige Minimum. Dabei können keine Fehler auftreten. Punkte werden aus drei Gründen entfernt:
Ad 1.) Numerisch gleichwertige aufeinanderfolgende Punkte können sich bei der Bearbeitung von CAD Plänen aus vielen Gründen ergeben. Optisch sind sie kaum zu erkennen, inhaltlich sind sie redundant, algorithmisch mitunter sogar schädlich.
Viele Systeme haben eine systematische Quelle numerisch gleichwertiger Punkte: die Wiederholung des ersten Punkts deutet in diesen an, dass die Punktaufzählung eines Polygons beendet ist. In recotech ist diese Information nicht notwendig und solche Punkte werden an dieser Stelle aussortiert um die Datenmenge möglichst klein zu halten.
Unter welchem Abstand voneinander zwei Punkte als numerisch gleichwertig gelten, kann der Benutzer einstellen.
|
|
Numerische Stabilität |
|
Selbst wenn beim minimalen Punktabstand in der GUI ein Wert von 0 möglich ist, kann die Säuberung der Punkte nicht völlig unterdrückt werden. Der tatsächlich verwendete Wert ist immer eine positive Zahl (mindestens ca. 10‑15). Das hat technische Gründe, die mit der Maschinendarstellung von Zahlen im Computer zusammenhängen. Mathematische Operationen im Computer sind nicht beliebig genau und ab einer gewissen Grenze werden Berechnungen fehlerhaft. |
|
Ad 2.) Ein Innenwinkel von annähernd 180° bedeutet, dass drei aufeinanderfolgende Punkte eine annähernd gerade Linie bilden. In vielen Systemen haben Polygone solche Punkte, weil andere Linien an dieser Stelle andocken. Für recotech ist diese Information nicht relevant und derartige Punkte verschlechtern nur die Performance. Sie werden also ebenfalls aussortiert.
|
|
Punktsäuberung bei Kreisen |
|
Gebogene Wände oder große Säulen werden üblicherweise durch Polygone mit relativ vielen Punkten dargestellt. Bei großer Genauigkeit kann es sein, dass alle Punkte in einem solchen Polygon im hier definierten Sinn numerisch zu ihren Nachbarn gleichwertig sind und/oder einen zu großen Innenwinkel bilden. |
|
Ad 3.) Ein Innenwinkel von annähernd 0° bedeutet eine sehr spitze Zacke im Polygon. Solche Zacken können sich bei der Bearbeitung oder Auswertung von CAD Plänen einschleichen und sind optisch kaum zu erkennen. Da auch diese Polygone die Begrenzungslinien von Räumen bzw. Raumzonen darstellen, sind sie inhaltlich unsinnig. Für die geometrischen Algorithmen in recotech sind sie teilweise schädlich. Auch hier gilt darum, wie bei der Säuberung der numerisch gleichwertigen Punkte, dass ein Mindestwinkel auch dann forciert wird, wenn der Benutzer 0° einstellt.
Wie viele Punkte die Säuberung entfernt hat wird neben dem Knopf angezeigt. Das sind immer nur die Ergebnisse der letzten Säuberung und dient nur der Information. Lediglich Punkte, die wegen zu kleiner Winkel aussortiert wurden, deuten auf mögliche Fehler in den Quelldaten hin.
Hier wird im Moment nur geprüft ob alle Polygone nach der Punktsäuberung noch mindestens drei Punkte besitzen. Polygone mit schneidenden Kanten sind optisch leicht zu erkennen, der entsprechende Test daher aus Performance Gründen im Moment deaktiviert. Aus den gleichen Gründen ebenfalls deaktiviert sind die Prüfungen auf sich überlappende Raumpolygone und die Prüfung ob Raumzonen Polygone vollständig innerhalb des Raums liegen.
Die Prüfung der Polygone setzt die Säuberung der Punkte voraus.
Hier werden alle Polygone gesucht, die zu den bestehenden Polygonen in den Stammdaten kongruent sind. Diese werden nur als Warnung hervorgehoben. Die entsprechenden Polygone und Punkte können mit dem Entfernen-Knopf aus der Tabelle entfernt werden. Diese Warnung kann aber auch ignoriert werden; unwirksame Anweisungen verhindern nicht den Datenimport.
Diese Prüfung setzt die Polygonprüfung voraus.
Hier werden alle Raum Datenimport Objekte als Fehler ausgewiesen, die kein Polygon besitzen. Davon können nur Einfügungen betroffen sein.
Hier wird für jeden Raum, in dem das in der Spalte 'Raumzone erzeugen' vermerkt ist, ein Raumzonen Datenaustauschobjekt als Einfügung erzeugt. Dies wird den gleichen Namen, die gleiche Größe und die gleiche Nutzungsart wie der Raum haben. Das Polygon entspricht dem äußeren Polygon des Raumes. Es ist dabei irrelevant, ob der Raum schon existiert oder ebenfalls erst erzeugt werden soll. Diese Aktion kann bei Bedarf also auch nach dem eigentlichen Import ausgeführt werden.
Die Erzeugung der Raumzonen setzt voraus, dass alle Räume Polygone haben.
Hier werden alle Raumzonen Datenimport Objekte als Fehler ausgewiesen, die kein Polygon besitzen. Davon können nur Einfügungen betroffen sein.
Die Positionspunkte der Raumzonen spielen in recotech eine entscheidende Rolle in den Entfernungs- und Nachbarschaftsberechnungen und damit in den Belegungsberechnungen. Die Entfernung zwischen zwei Raumzonen eines Raumes ist die kürzeste Linie zwischen deren Positionspunkten. Die Entfernung zu den Raumports ist die zwischen den Positionspunkten der Raumzonen und der Raumports. Von dort werden die Entfernungen zu allen anderen Raumzonen gesucht.
Deshalb ist es wichtig, dass die Positionierungspunkte auch tatsächlich im Polygon der Raumzone liegen. Sie zur Kontrolle in der recotech Grafik anzuzeigen wäre möglich, würde aber nicht ausreichen, weil die entscheidende Information, ob ein solcher Punkt auch logisch zu der Raumzone gehört, in der er liegt, auch damit nicht sichtbar wird.
Fehler bei diesen Positionierungspunkten sind also schwer zu entdecken und können zu unsinnigen Belegungsergebnissen führen. Deshalb wird hier verifiziert, dass alle Positionierungspunkte auch tatsächlich in dem Polygon ihrer referenzierten Raumzone liegen.
Wenn die Koordinatenfelder in den Raumzonen Datenimport Objekten den Spezialstring für die geometrische Berechnung haben, wird ein passender Punkt errechnet und diese Strings durch Zahlangaben ersetzt. Dabei wird der Schwerpunkt des Polygons ermittelt und gegebenenfalls auf die nächstliegende Kante verschoben, falls dieser Schwerpunkt außerhalb liegen sollte.
|
|
Koordinaten: Syntax und Semantik |
|
Selbst wenn in den Quelldaten das Pendant einer recotech Raumzone über ein Koordinatenpaar verfügt, sollte man sich von der syntaktischen Übereinstimmung nicht vorschnell leiten lassen. Nur wenn diese Punktangabe auch tatsächlich als eine Positionsangabe der Raumzone gemeint ist sollte sie in recotech verwendet werden. Mit großer Wahrscheinlichkeit sind solche Daten Label Positionen in einem CAD-Plan. Solche Labels sind zwar meist in der Nähe der Flächen, die sie qualifizieren, ihre genaue Position hat aber meistens mehr mit der Übersichtlichkeit der Zeichnung als mit wirklichen Positionsangaben zu tun. |
|
Die Überprüfung vorhandener Angaben verwendet genau den gleichen Algorithmus wie die Berechnung des Positionspunktes. Deshalb wird ausdrücklich empfohlen, die Positionspunkte immer berechnen zu lassen.
Die Überprüfung der Raumzonen Positionspunkte setzt die Prüfung der Raumzonenpolygone voraus.
Die letzte geometrische Prüfung verifiziert, dass die angegebenen Räume an den Raumports und die Positionspunkte dieser Ports inhaltlich kompatibel sind.
Jede Datenstruktur, die zu einer Tür eine Position und einen oder zwei Räume speichert, erlaubt potentiell unsinnige Daten: die Position kann von einem oder sogar beiden Räumen weit entfernt sein und die beiden Räume müssen nicht benachbart sein.
Fehlerhafte Raumverknüpfungen an Türen führen dazu, dass tatsächlich weit auseinanderliegende Räume logisch verbunden sind und/oder dass tatsächlich genau nebeneinander liegende Räume logisch nicht verbunden sind. Dieser Fehler ist in grafischen Darstellungen nicht sichtbar. Der menschliche Betrachter nimmt einfach an, dass eine Tür die beiden Räume verbindet, in deren gemeinsamer Wand sie liegt. Deshalb tritt dieser Fehler auch in gut gepflegten Daten erstaunlich häufig auf.
In recotech äußert sich dies in scheinbar fehlerhaften Belegungen (und damit Zweifel am Belegungsalgorithmus), weil die falschen Raumverknüpfungen falsche Nachbarschaftsbeziehungen darstellen.
Deshalb wird hier verifiziert, dass die beiden angegebenen Räume tatsächlich in unmittelbarer Nähe des angegebenen Positionierungspunktes liegen. Dies ist der einzige Fall, in dem recotech eine möglicherweise gewollte (wenn auch sehr seltsame) Modellierungsentscheidung aus inhaltlichen statt aus technisch notwendigen Gründen als Fehler ablehnt.
Wenn einer oder beide Verweise und Referenzen auf die verbundenen Räume in den Datenimportobjekten der Raumports den Spezialstring für die geometrische Berechnung haben, werden die zwei nächstliegenden Räume des Geschosses ermittelt und als Werte gesetzt. Allerdings auch nur, wenn die Entfernungen zu diesen Räumen unter dem angegebenen Maximum liegen.
Die Berechnung eines Positionierungspunktes anhand der beiden verbundenen Räume ist zurzeit noch nicht möglich.
Auch wenn Fehler durch die Erhöhung der maximalen Entfernung scheinbar beseitigt werden können, wird ausdrücklich geraten, dies nicht zu tun. Es ist eigentlich kein Fall denkbar, in dem eine Tür von einem ihrer verbundenen Räume allzu weit entfernt liegt.
|
|
Häufiger Fehler: Türentfernung und innere Polygone |
|
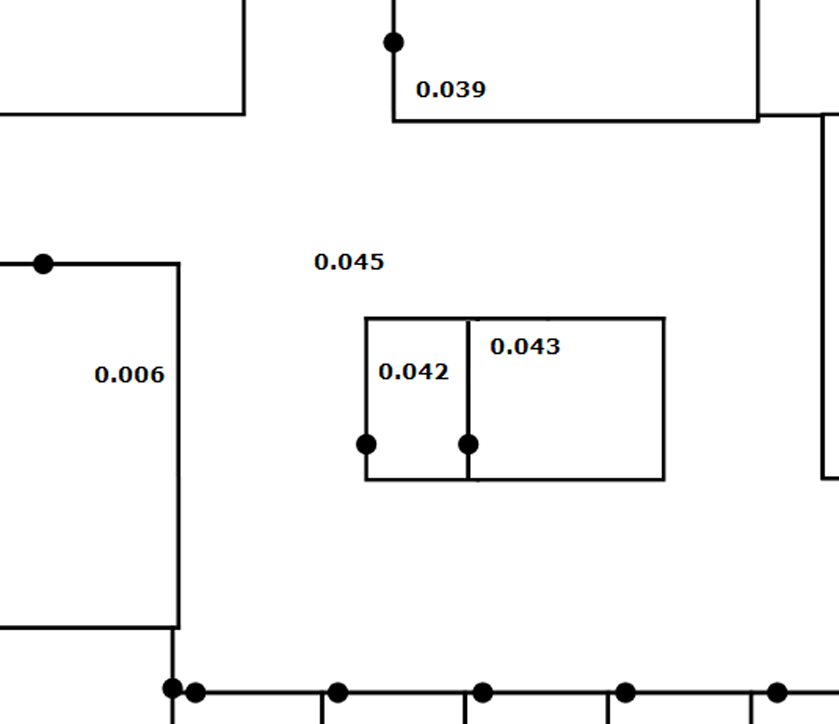
Im Laufe der Port Positionsprüfung kommt es häufig zu einem Fehler, dessen Ursachen tatsächlich an ganz anderer Stelle zu suchen sind.
Oft kommt es in diesem Zusammenhang zu folgender Situation: Die Port Positionsprüfung weist diese Tür als fehlerhaft aus. Der Fehler verschwindet, sobald die Maximaldistanz auf etwa zwei Meter eingestellt wird. Lässt man die Räume anhand der Portposition berechnen, verbindet die Tür nun plötzlich die Räume 0.042 und 0.043, weil das die beiden Räume sind, die Wände besitzen, die näher an der Tür liegen als die aller anderen Räume (die nächste Wand des Raums 0.045 ist die gegenüber liegende zum Raum 0.006). Der Fehler liegt weder in der Tür noch in der Prüfung, sondern darin, dass die Entfernungsberechnung der Tür zum Raum 0.045 nur das äußere Polygon verwendet hat. Für solche innenliegenden Räume müssen auch die inneren Polygone gesetzt werden. Wenn die Portpositionsprüfung Türen als fehlerhaft ausweist, die solche innen liegenden Räume mit dem umliegenden Raum verbinden, liegt das in den allermeisten Fällen daran, dass das innere Polygon vergessen wurde. Der Fehler ist besonders tückisch, weil er rein optisch nicht zu erkennen ist. |
|