Importmodul IV: Importprofil |
Einfache Deklarationen und Bedingungen
Komplexe Deklarationen und Bedingungen
Anhang II : Typen- und Attributs Bezeichner
Änderungshistorie
|
Datum |
Beschreibung |
|
04.07.2012 |
Erstellung des Dokumentes |
|
05.09.2012 |
Ergänzung in Zielbedingungstabelle |
Über dieses Dokument
Das in diesem Dokument beschriebene Importprofil ist ein Bestandteil des recotech Importmoduls. Es dient speziell dem Einlesen von Daten aus CSV-, Excel- oder ähnlichen Dateien.
Welche Daten recotech benötigt, ist Gegenstand des Dokuments "Importmodul I: Objekte und Daten". Die generelle Funktionsweise des Importmoduls wird im Dokument "Importmodul II: Aufbau und Überblick" dargestellt und der Verarbeitung der Importdaten ist das Dokument "Importmodul III: Datenverarbeitung" gewidmet.
Die Kenntnis dieser Dokumente wird hier vorausgesetzt.
Nur in den seltensten Fällen werden die Quelldaten in der Struktur vorliegen, die das recotech Importmodul verwendet. Die Quelltabellen werden im Allgemeinen andere Spalten in anderer Reihenfolge und anderer Benennung haben. Manche Attribute an recotech Importobjekten sind in den Quelldaten vielleicht das Attribut eines per Fremdschlüssel verknüpften Objektes, des selbst gar nicht importiert wird; die Daten für diese recotech Importtabelle wären also über mehrere Quelltabellen verteilt. Umgekehrt kann es auch sein, dass aus einer Quelltabelle mehrere recotech Importtabellen gespeist werden, wobei manche Spalten möglicherweise an mehreren Stellen verwendet werden müssen.
Die korrekte Auswahl der Quelldaten und die Überwindung solcher struktureller Unterschiede sind einfach, wenn die Importdaten per SQL direkt aus einer Quelldatenbank in die Importtabellen der recotech Datenbank geschrieben werden. Falls die Quelldaten aber nur in Form von CSV-, Excel oder ähnlichen Dateien vorliegen, stellen sie eine gewisse Hürde dar. Insbesondere manuell erstellte Excel Dateien enthalten oft Zwischenüberschriften oder andere Formatierungen, die der Lesbarkeit durch menschliche Benutzer dienen, beim Abspeichern im CSV Format aber zu störenden Artefakten führen.
Solche Dateien manuell an die Struktur der recotech Importdaten anzupassen ist im Prinzip möglich, aber mühselig und fehleranfällig. Das recotech Importmodul kann deshalb Daten aus CSV Dateien gezielt extrahieren und dabei auch transformieren. Ein Großteil der notwendigen Umformatierung lässt sich damit automatisieren. Im Importprofil werden die Regeln für diese Extraktion, die Transformationen und die Zuordnungen zu den Zielspalten konfiguriert.
Das Importprofil ist eine Klartext-Datei, die vom Importmodul ausgelesen und interpretiert wird. Ihr Inhalt und Aufbau muss deshalb gewissen Regeln entsprechen. Die grundlegenden Datenzuordnungen und Transformationen sind für jeden Benutzer verständlich und leicht anzupassen. Komplexere Transformationen erfordern eine gewisse Vertrautheit mit Datenstrukturen und Programmierung. In diesem Dokument werden zunächst die Grundfunktionen beschrieben. Den fortgeschrittenen Möglichkeiten ist ein eigenes Kapitel gewidmet.
|
|
Schematischer Überblick |
|
|
|
||
|
|
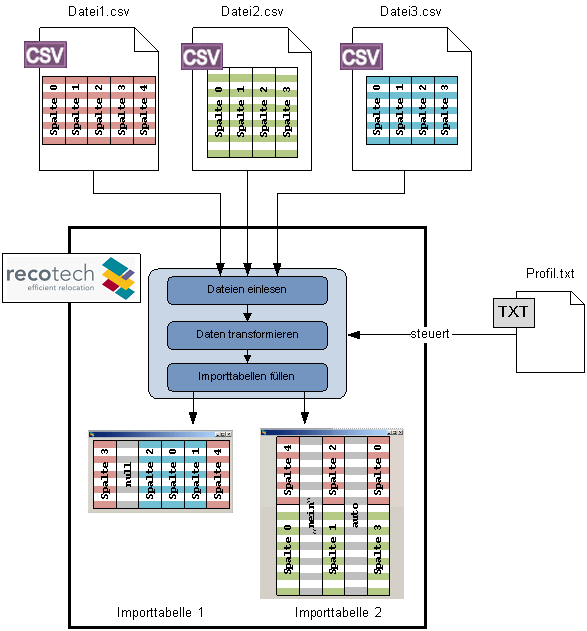
Die obige Grafik skizziert den Extraktionsprozess. Oben sind drei Dateien im CSV-Format dargestellt. Ihre Spalten werden symbolisch durch gestreifte Säulen repräsentiert, deren Höhe die Anzahl der Datensätze andeutet. Die aus diesen Säulen zusammengestellten Rechtecke im unteren Teil symbolisieren zwei Tabellen mit recotech Importobjekten, also die Zieltabellen oder die Datensenken. Die Pfeile symbolisieren die Datenflüsse. Wie man sieht, sind die Informationen für die zweite Importtabelle auf zwei Dateien verteilt, die beide alle vorhandenen Informationen für die erste Importtabelle enthalten, allerdings in verschiedenen Spalten. Die entsprechenden Spalten werden also untereinander in die gleiche Zielspalte geschrieben. |
|