Importmodul II: Aufbau und Überblick |
Änderungshistorie
|
Datum |
Beschreibung |
|
20.07.2012 |
Erstellung des Dokumentes |
|
31.07.2012 |
Rechtschreibungs- und Formulierungskorrekturen |
Über dieses Dokument
Das recotech-Importmodul ist weniger eine Schnittstelle im klassischen Sinne als vielmehr ein Werkzeug zum Abgleich der recotech-Stammdaten mit einem externen Datenbestand. Bezüglich der Struktur und Formatierung des Letzteren werden nur geringe Ansprüche gestellt. Allein die inhaltliche Kompatibilität ist entscheidend. Siehe dazu das Dokument "Importmodul I: Objekte und Daten". Auch wenn sich darin keine tabellarischen Übersichten über Datentypen finden und das ganze Dokument wesentlich weniger technisch ist, als das vorliegende, ist es doch für die Frage "Was für Daten braucht recotech?" das ungleich wichtigere und sollte unbedingt zuerst gelesen werden!
Im vorliegenden Dokument stehen der Aufbau des Importmoduls und seine Stellung im recotech-System im Mittelpunkt. Daraus ergeben sich mögliche Abläufe des Datenaustauschs.
Zudem befinden sich hier die technischen Spezifikationen der benötigten Daten. Weil das Recotech-Importmodul bezüglich Struktur und Format der Quelldaten so gut wie keine Voraussetzungen stellt, geht es hier nicht um die in Schnittstellenbeschreibungen üblichen Angaben bezüglich Format und Struktur der Daten, sondern vielmehr um die vielfältigen Möglichkeiten der Datenvervollständigungen.
Der genaue Ablauf der Datenverarbeitung wird im Dokument "Importmodul III: Datenverarbeitung" beschrieben. Dort wird auch erklärt, wie der Anspruch der Struktur- und Formatunabhängigkeit eingelöst wird, wo die entsprechenden Funktionen in der Benutzeroberfläche zu finden sind und wie die Datenpflege und der Datenabgleich auch ohne gemeinsame IDs funktioniert.
Der Möglichkeit des konfigurierbaren kontrollierten Einlesens von spaltengetrennten Textdateien (CSV, Excel oder äquivalenten Formaten) ist wegen der Vielzahl der damit verbundenen Möglichkeiten ein eigenes Dokument gewidmet. Siehe dazu: "Importmodul IV: Importprofil"
Die tabellarischen Übersichten der einzelnen Objekttypen im vorliegenden Dokument sind ausdrücklich nicht so zu verstehen, dass die Quelldaten in dieser Form vorliegen müssen. Es ist völlig ausreichend, wenn die entsprechenden Informationen irgendwie in einer Datenbank oder in CSV, Excel oder ähnlichen Dateien verfügbar sind.
Das Recotech-Importmodul ist eigens für den Abgleich der Recotech-Daten mit Fremddaten in fast beliebiger Formatierung und Struktur entwickelt.
Es erzeugt aus den Fremddaten zunächst spezielle Importobjekte. Diese Importobjekte, und damit die benötigten Importdaten, sind maximal anspruchslos: Ihre Attribute sind beliebige Zeichenketten (auch numerische Angaben) ohne feste Formatvorgabe. Sie erlauben fast beliebige Lücken, IDs zum Bezug auf recotech-Daten sind optional und auch die Beziehungen der Importobjekte untereinander können per ID, temporärer ID, nur inhaltlich oder in beliebiger Mischung ausgedrückt werden. Bei Importdaten in Form von CSV-Dateien, Excel-Tabellen oder Dateien in äquivalentem Format gibt es keine Vorgaben bezüglich Bezeichnung, Anzahl, Struktur dieser Dateien und deren Spalten.
Das Importmodul akzeptiert also erst mal so gut wie alles. Vollständigkeit und Korrektheit der Daten sind keine Voraussetzungen für das Importmodul. Sie herzustellen bzw. zu verifizieren ist vielmehr eine seiner zentralen Aufgaben. Fehler und Probleme werden in seiner Programmoberfläche angezeigt und können dort behandelt werden. Dazu können selbst fehler- oder lückenhafte Daten erfasst werden. Das Importmodul ist eher eine Mischung aus Import Wizard und Datenanalysetool, als eine klassische Schnittstelle.
Auf die Importobjekte werden im Importmodul eine ganze Reihe von Prüfungen, Analysen und Vervollständigungen angewandt. Unter anderem:
Für eine detaillierte Beschreibung dieser Funktionen und des Verarbeitungsprozesses der Importdaten siehe "Importmodul III: Datenverarbeitung".
Der Fortschritt und die Ergebnisse dieser Prüf- und Bearbeitungsalgorithmen lassen sich in der grafischen Benutzeroberfläche (GUI) des Importmoduls verfolgen. Die entsprechenden Funktionen können auch manuell angestoßen werden. Fehler oder Probleme werden transparent dargestellt und der Benutzer kann jederzeit korrigierend eingreifen.
Mit Hilfe der Import-GUI ist auch der flexible und improvisierte Import von Daten einer zuvor nicht bekannten Datenquelle sicher und kontrolliert möglich.
Beim Datenabgleich mit einer systematischen Quelle (wie einem anderen datenbankbasierten System) dienen die vielfältigen Möglichkeiten der Import-GUI hauptsächlich der korrekten Konfiguration und Erprobung des Importprozesses.
Beim routinemäßigen Import von Daten aus einer bekannten Quelle läuft der Importprozess automatisch ab.
Das Ergebnis des Verarbeitungsprozesses ist eine vollständige Liste aller Änderungen an den recotech-Daten, die der Import- bzw. Datenabgleich bewirken wird. Erst im zweiten Schritt werden diese Änderungen auf die eigentlichen recotech-Daten angewandt. Ein direkter Zugriff auf die Stammdatentabellen in der Datenbank von außen ist nicht vorgesehen.
|
|
Importobjekt = Datensatz = Anweisung |
|
Die drei Termini "Importobjekt", "Datensatz" und "Anweisung" sind, wenn sie sich auf einen Datensatz im recotech Importmodul beziehen, synonym. Je nach dem welcher Aspekt dieser Objekte im gegebenen Kontext gerade relevant ist, wird mal das eine, mal das andere Wort verwendet. |
|
Um den Datenimport durchzuführen, müssen recotech gestartet, die Austauschtabellen gefüllt, der Datenimport angestoßen und die neuen Stammdaten abgespeichert werden.
Die Datensätze in den Importtabellen entsprechen ungefähr den eigentlichen Stammdaten, sie werden aber nicht direkt in die Stammdaten geschrieben. Stattdessen werden die gefüllten Importtabellen inhaltlich interpretiert, automatisch vervollständigt, auf Konsistenz geprüft, in Anweisungen für das Importmodul übersetzt und schließlich ausgeführt.
Dieses Verfahren dient folgenden Zwecken:
Alle Spalten in allen Importtabellen sind vom Datentyp String. Das gilt insbesondere auch für Felder, die in den Stammdaten numerische oder boolesche Werte haben. Es gibt also keine Vorgaben bezüglich der Darstellung.
Diese größtmögliche Flexibilität sowie die inhaltliche Interpretation und Überprüfung der Daten im Importprozess dient dem systematischen Datenimport aus beliebig formatierten, möglicherweise unvollständigen und evtl. inhaltlich lücken- und fehlerhaften Excel-Tabellen. Solche Excel-Tabellen dienen als Beispiel für die Lingua franca, den Worst Case und den kleinsten gemeinsamen Nenner der Datenhaltung. Der leitende Gedanke bei der Entwicklung des Importmoduls war, dass alles andere ein vergleichsweise einfacher Spezialfall ist.
Für den systematischen Austausch mit anderen datenbankbasierten Systemen sind viele der Möglichkeiten nicht notwendig, können aber auch hier hilfreich sein.
Die nachfolgende Grafik gibt einen Überblick über die Datenflüsse, wobei die des Imports rot, die möglichen Exportdatenflüsse (jeweils aus Sicht von recotech) grün gefärbt sind.
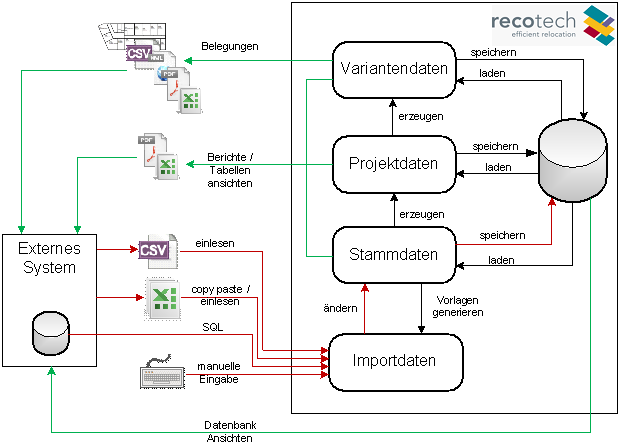
|
|
Stamm-, Projekt und Variantendaten |
|
In recotech gibt es drei Datenebenen, die Stamm-, Projekt- und Variantendaten. Die Stammdaten stellen den aktuellen Istzustand dar. Aus diesen können beliebige Projekte erzeugt werden. Ein Projekt ist eine Untermenge der Stammdaten, die alle Elemente umfasst, die im Rahmen eines konkreten Planungsvorhabens eine Rolle spielen. In jedem Projekt können wiederum beliebige Varianten erstellt werden, in denen die eigentliche Planung inklusive aller Berechnungen stattfindet. Projekt- und Variantendaten haben hypothetischen Status. In ihnen vorgenommene Änderungen und Anpassungen haben nur Probecharakter. Beliebige Szenarien sollen durchgespielt und miteinander verglichen werden können, ohne dass die Stammdaten oder andere Planungen/Szenarien davon betroffen sind. Anders herum sollen bestehende Projekte von den Stammdaten unabhängig sein, damit alte Planungen erhalten bleiben, selbst wenn manche der involvierten Elemente in den Stammdaten gelöscht werden. Bei der Erstellung von Projekten und Varianten werden die beteiligten Daten deshalb kopiert. Die Kopien verweisen immer noch auf die Originale, um die im Rahmen einer Planung vorgenommenen Änderungen, d. h. Abweichungen vom Istzustand, transparent zu halten. Zwischen Varianten und ihrer Basis, dem Projekt, ist dieser Bezug auf das Vorlageelement Grundlage für ständige Synchronisierung. Um die Vergleichbarkeit verschiedener Varianten eines Projektes sicherzustellen, müssen in allen Varianten eines Projektes immer die gleichen Elemente repräsentiert sein. Deshalb können in einer Variante Elemente nur geändert aber nicht gelöscht werden. Die Zusammensetzung von Varianten ist nur indirekt über das zugrunde liegende Projekt änderbar und betrifft dann immer alle Varianten dieses Projektes. Zwischen Projekten und Stammdaten ist dieser Bezug zum Vorlageelement deutlich schwächer. Elemente in den Stammdaten können gelöscht werden, auch wenn es noch Elemente in Projekten gibt, die auf sie als ihre Originale verweisen. Diese Verweise gehen dann einfach ins Leere. Dieser Umstand erlaubt im Prinzip die radikalste Methode der Stammdatenpflege: alles zu löschen und neu zu importieren, die Stammdaten also komplett auszutauschen. Damit sind allerdings versteckte Probleme verbunden, auf die weiter unten eingegangen wird. |
|
Aufbau und Verfahren des recotech-Importmoduls sind darauf ausgerichtet, die Hürden für den Datenimport so gering wie nur möglich zu halten. Es werden nur zwei Annahmen getroffen, die erfüllt sein müssen:
In den seltensten Fällen haben unsere Kunden die von recotech benötigten Daten in einem einzigen datenbankbasierten System. In vielen Fällen stammen die Daten gar nicht aus einer anderen Datenbank, sondern liegen in Form von mehr oder weniger einheitlich strukturierten bzw. gepflegten Excel Listen und CAD Plänen vor. Dementsprechend selten gibt es verwendbare externe IDs oder wiederkehrende Datenstrukturen.
Auch für Kunden, deren Daten in datenbankbasierten Systemen gehalten und gepflegt werden, hat dieser Ansatz erhebliche Vorteile. In der Regel entscheidet ein Pilotprojekt über den Einsatz von recotech. Die Programmierung einer vollständigen Datenintegration hierfür wäre zu aufwändig. Mit dem recotech-Importmodul kann auch kundenseitig der erste Datenimport schnell und flexibel durchgeführt werden. Im Laufe des Pilotprojektes anfallende Änderungen und Aktualisierungen können ebenso unkompliziert eingepflegt werden. Datenbank- bzw. IT-Kenntnisse sind dafür nicht notwendig.
Alle in den Datenstrukturen versteckten Probleme bezüglich Vollständigkeit und Verträglichkeit der Daten, die eine später vielleicht erfolgende Integration von recotech in die Geschäftsprozesse oder IT-Landschaft verzögern oder erschweren werden, treten so bereits im Pilotprojekt auf. Mit diesen Erfahrungen kann eine verlässliche Aussage darüber getroffen werden, ob die vorhandenen Daten ausreichend und mit recotech kompatibel sind, bzw. welcher Aufwand bei eventuell später zu erfolgender Integration zu erwarten ist. Der Datenfluss ist dann bereits erprobt und muss nur noch automatisiert werden. Und auch dabei dient das Importmodul als Testumgebung mit einer grafischen Benutzeroberfläche zur Fehler- und Problemanalyse. Eine ähnlich gute Basis für die Planung bzw. Umsetzung einer Datenintegration können nach unseren Erfahrungen theoretische Schnittstellenspezifikationen und Datenbeschreibungen nicht liefern.
Ein weiterer, insbesondere für Kunden mit komplexer IT-Landschaft entscheidenderer, Vorteil ist folgender: Jede Form der doppelten Datenhaltung, wie sie der parallele Einsatz mehrerer Systeme mit sich bringt, birgt die Gefahr der Dateninkonsistenz. Eine übliche Methode, dem zu begegnen, besteht in der Implementierung einer eigens für diese beiden Systeme geschaffenen Schnittstelle, welche die Daten automatisch und kontinuierlich synchronisiert. Implementierung, Betrieb und Pflege solcher Systemschnittstellen sind allerdings mit erheblichen Kosten und Risiken verbunden.
Der hier verfolgte Ansatz geht von dem Szenario als dem Normalfall aus, das für inkrementell und in Echtzeit arbeitende Schnittstellen der Worst Case ist: die zwei Datenbestände sind auseinandergelaufen und müssen wieder zusammengeführt werden. Das recotech-Importmodul wurde speziell hierfür entwickelt. Kontinuierliche Pflege und Synchronisierung sind ein besonders einfacher Spezialfall und nur dann erforderlich, wenn recotech im Tagesgeschäft eingesetzt werden soll.
Die einfachste und zugleich zuverlässigste Möglichkeit des Datenabgleichs wurde bereits erwähnt: alles zu löschen und neu zu importieren. Diese Methode hat weder die Nachteile einer Systemintegration mittels Schnittstelle noch die Komplexität einer echten Datenzusammenführung.
recotechs Stärke ist die Verwaltung, Darstellung und Berechnung vieler hypothetischer Belegungsszenarien. Dazu benötigt es nur vergleichsweise wenige Daten aus dem Bereich der Personal- und Immobilienverwaltung. In Firmen, die SAP, mächtige CAFM Systeme oder Ähnliches einsetzen, wird recotech kaum das führende System sein. Die Radikalmethode der Datenpflege ist also nicht nur möglich, sie scheint sich sogar anzubieten. Wie bereits angedeutet sind damit allerdings versteckte Nachteile verbunden, die mit der Szenarien-Verwaltung und der damit verbundenen vielfachen Datenverdopplung in recotech zusammenhängen.
|
|
Probleme beim vollständigen Datentausch 1: Personendaten |
|
In recotech werden keine Personen verteilt, sondern Platzansprüche. Diese stellen einen abstrakten Flächenbedarf dar. Die Verknüpfung zu Personen ist optional. Für die Belegungsplanung ist es letztlich irrelevant, welche reale Person eine bestimmte Tätigkeit ausübt. Der Flächenbedarf ist an diese Tätigkeit und die damit verbundene Stelle in der Organisation gebunden. Die Erfassung von Personen ist teilweise aus Datenschutzgründen auch gar nicht erwünscht. Personen haben in recotech nur Namen und ein Kommentarfeld. Da Änderungen in diesen Feldern für die Belegungsplanung ohne Bedeutung sind, werden die Personen nur in den Stammdaten gepflegt und beim Erstellen von Projekten und Varianten nicht mit kopiert. Sie wären dort nur unnötiger Ballast, der gepflegt werden muss, wenn sich die Personalsituation während einer Planung ändert. Wenn in den Belegungsplänen oder -berichten Personennamen angezeigt werden, geschieht dies über die Verknüpfung des Platzanspruchs in der Variante zu seinem Basisobjekt im Projekt und von dort zu dem in den Stammdaten. Nur das Letzte hat Verknüpfungen zu Personen, deren Namen dann in der Darstellung der Variante zur Verfügung stehen. Durch einen kompletten Austausch der Stammdaten geht die entscheidende Verknüpfung des Projektobjektes zu seinem Original in den Stammdaten verloren. Es ist dann in den Projekten und Varianten nicht mehr möglich, zu einem Platzanspruch die mit ihm verbundenen Personen zu ermitteln oder anzuzeigen. |
|
|
|
Probleme beim vollständigen Datentausch 2: Datenpflege und Objektidentität |
|
Es macht datentechnisch einen großen Unterschied, ob ein bestehendes Objekt geändert wird oder ob es durch ein neues ersetzt wird. Der menschliche Benutzer identifiziert Objekte anhand ihrer Attribute. Für ihn steht ein Stammdaten-, Projekt- oder Variantenraum z. B. für den einen Raum 0815 in dem einen Erdgeschoss des einen Gebäudes Müllerstrasse 5. Für ein IT-System ist es aber nur das Objekt mit einer gegebenen ID und weiteren IDs als Verweise auf andere Objekte. Normalerweise ist es nicht möglich, zwei Datenobjekte für das gleiche reale Objekt in einem Projekt zu haben. Das wird über den Verweis auf das Stammdatenobjekt sichergestellt. Ein neu angelegtes Objekt unterliegt dieser Beschränkung nicht, auch wenn es nach menschlichem Dafürhalten das gleiche reale Objekt repräsentiert. Nach einem kompletten Austausch der Stammdaten ist der Schutz vor solchen Doubletten damit nicht mehr möglich. Ein Raum könnte also zweimal in einem Projekt repräsentiert sein, wenn er vor und nach dem Komplettaustausch der Stammdaten diesem Projekt zugeordnet wird. Solche Dubletten nach der kompletten Auswechslung der Stammdaten kann der Benutzer natürlich vermeiden, indem er sich des Problems bewusst ist und die Änderung der Zusammenstellung zuvor angelegter Projekte unterlässt. Im Datenimport werden solche Dubletten vermieden, egal ob er mit oder ohne IDs durchgeführt wird. Die Objektidentifikation ist auch inhaltlich möglich, sofern genügend Attribute gleich bleiben, die zur Identifizierung verwendet werden können. Für den regulären Betrieb von recotech sind die dabei verwendeten Algorithmen allerdings zu ineffizient. Hier wird, wie generell üblich, nur die ID zur Objektidentifikation herangezogen. In Projekten und Varianten sind substanzielle und möglicherweise identitätsgefährdende Änderungen nicht möglich. Beim Import von Daten mit externen IDs werden die inhaltlichen Identifizierungsalgorithmen weitestgehend umgangen. Beliebige und radikale Änderungen an einem Objekt sind möglich. Die Entscheidung, welche Änderungen mit der fortlaufenden Objektidentität noch sinnvoll zu vereinen sind, liegt in der Verantwortung des Benutzers bzw. des Quellsystems. Die Gefahr der unsinnigen Identifizierung hindert recotech daran, statt der eigenen internen ID nur die externe ID eines Fremdsystems für die Stammdaten zu verwenden. Damit würde bei einem Komplettaustausch der Stammdaten den Projekten zwar nicht ihre Basis weggenommen, aber nicht nur der Datenaustausch mit einem Fremdsystem, das IDs von gelöschten Objekten wiederverwendet, sondern auch die internen Prozesse von recotech wären mit solchen Daten nicht mehr sicher. |
|



